Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- How to create a function or Script for string mapp...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to create a function or Script for string mapping with percentages
I would like to compare the names in the same column, for this I want to write a code in the script editor or a function in the object. can anyone help me on this?
Below is the example:
Account Names:
Accenture Pvt Ltd
Accenture Private Limited
Hitachi Systems Ltd
Hitachi System Limited
Us Department of Army
United States Department of Army
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What is the expected output here?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sunny,
We have one dataset, from that dataset (Like self-join in SQL) itself we need to identify possible matches with some %ge criteria.
Dataset:
Account Names:
Accenture Pvt Ltd
Accenture Private Limited
Hitachi Systems Ltd
Hitachi System Limited
Us Department of Army
United States Department of Army
Expected output should be like...
| Account Names | AccountName_Match |
| Accenture Pvt Ltd | Accenture Pvt Ltd |
| Accenture Pvt Ltd | Accenture Private Limited |
| Accenture Private Limited | Accenture Private Limited |
| Accenture Private Limited | Accenture Pvt Ltd |
| Hitachi Systems Ltd | Hitachi Systems Ltd |
| Hitachi Systems Ltd | Hitachi System Limited |
| Hitachi System Limited | Hitachi System Limited |
| Hitachi System Limited | Hitachi Systems Ltd |
| Us Department of Army | Us Department of Army |
| Us Department of Army | United States Department of Army |
| United States Department of Army | United States Department of Army |
| United States Department of Army | Us Department of Army |
and the %ge match.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think this is something marcowedel might be able to help you with.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
may be this will help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Check attached QVW. Your solution can be used with a combo of Wildmatch and ApplyMap (or alteratively with MapSubString for exact string matches - however, this method is 'case sensitive', the Wildmatch solution below isn't 'case sensitive').
The solution in this QVW allows you to look for a string of sequenced letters if it is a 'free text' field you are searching through and you believe that there is a minimum amount of letter sequence needed to match the ultimate result/grouping you want to get.
(Can't attach QVW, so script is below, copy/paste exactly and play around with the "WildmatchStrings_Temp" table and change the FACT table contents to see how it works. Put a table in front end with the 2 resulting fields to understand how it works).
SET ThousandSep=',';
SET DecimalSep='.';
SET MoneyThousandSep=',';
SET MoneyDecimalSep='.';
SET MoneyFormat='£#,##0.00;-£#,##0.00';
SET TimeFormat='hh:mm:ss';
SET DateFormat='DD/MM/YYYY';
SET TimestampFormat='DD/MM/YYYY hh:mm:ss[.fff]';
SET MonthNames='Jan;Feb;Mar;Apr;May;Jun;Jul;Aug;Sep;Oct;Nov;Dec';
SET DayNames='Mon;Tue;Wed;Thu;Fri;Sat;Sun';
SET LongMonthNames='January;February;March;April;May;June;July;August;September;October;November;December';
SET LongDayNames='Monday;Tuesday;Wednesday;Thursday;Friday;Saturday;Sunday';
SET FirstWeekDay=0;
SET BrokenWeeks=0;
SET ReferenceDay=4;
SET FirstMonthOfYear=1;
SET CollationLocale='en-GB';
//Script start here
WildmatchStrings_Temp:
//2. Create a numerical equivalent for each line/string of data in table:
LOAD *, Rowno() as OrdinalPosition;
//1. Original strings against which you are trying to match:
LOAD * INLINE [
Clean_Name_as_Category, WildMatchString
Accenture, accenture
Hitachi, hitachi
US Department of Army, u*s*d*p*t*army
];
//Create a field with all strings which you will put in a variable and is sequentially 'ordered' as it is in above table:
Var_WildMatchString:
LOAD CHR(39) & '*' & Concat(DISTINCT WildMatchString, '*' & CHR(39) & ',' & CHR(39) & '*', OrdinalPosition) & '*' & CHR(39) as Var_WildMatchString RESIDENT WildmatchStrings_Temp;
//Insert value in var:
LET vVar_WildMatchString = PEEK('Var_WildMatchString', 0, 'Var_WildMatchString');
DROP TABLE Var_WildMatchString;
//Reload table as Mapping table:
WildMatch_Map:
MAPPING LOAD
OrdinalPosition,
Clean_Name_as_Category
RESIDENT WildmatchStrings_Temp;
DROP TABLE WildmatchStrings_Temp;
THE_FACT_TABLE:
LOAD
*,
ApplyMap('WildMatch_Map', WildMatchOrdinalPosition) as Clean_Name_as_Category
;
LOAD
*,
Wildmatch(AccountNames, $(vVar_WildMatchString)) as WildMatchOrdinalPosition,
MapSubString(
;
LOAD * INLINE [
AccountNames
Accenture Pvt Ltd
Accenture Private Limited
Accenture Consulting
Hitachi Systems Ltd
Hitachi System Limited
Hitachi France
Us Department of Army
United States Department of Army
us dept army
];
//end script here
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You could approach this as a Wildcard mapping problem. An example of Mapping with Wildcards can be found here.
Qlikview Cookbook: Mapping With Wildcards http://qlikviewcookbook.com/recipes/download-info/mapping-with-wildcards/
You can also use the Qvc.CreateWildmapExpression routine in QVC http://qlikviewcomponents.org which does the same thing as the example.
-Rob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'd be happy to be proven wrong but I think this goes beyond the normal scope of a BI application. If your set of account names runs to a large number with all sorts of variations in how the names are recorded then you may need an application (think R, Matlab, Octave or something along those lines) running an algorithm that has been suitably trained.
Good luck
Andrew
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Andrew,
I run across this requirement fairly often in QV. It's usually just as the OP's example, variations on company names. I tackle it with a mapping table or wildcard mapping.
-Rob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
maybe this approach matches your requirements?
Using your example one solution might look like:
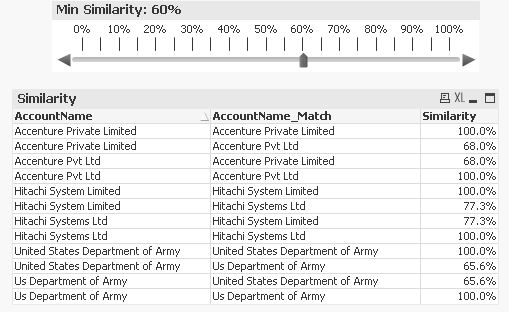
tabAccountNamesTemp:
LOAD * INLINE [
AccountName
Accenture Pvt Ltd
Accenture Private Limited
Hitachi Systems Ltd
Hitachi System Limited
Us Department of Army
United States Department of Army
];
Join
LOAD AccountName as AccountName_Match
Resident tabAccountNamesTemp;
tabAccountNames:
LOAD AccountName,
AccountName_Match,
Num(1-Levenshtein(AccountName,AccountName_Match)/RangeMax(Len(AccountName),Len(AccountName_Match)),'0.0%') as Similarity
Resident tabAccountNamesTemp;
DROP Table tabAccountNamesTemp;
hope this helps
regards
Marco
- « Previous Replies
-
- 1
- 2
- Next Replies »