Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- How to make script reload faster while developing ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to make script reload faster while developing and testing?
Our project script take more then 5 minutes to reload. I don't know if this is a lot or not, but seems quite a lot for me. When I am writing a script and need to test often, this is very time consuming to wait that long.
Please provide some techniques to make reload faster during development and testing. Maybe we are doing bad joins or using residents wrongly etc etc.
(I don't much care (now) how long it will take when it will be done and reloading on daily basis).
Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
During develepping/testing you probably don't need to have the whole data. You can reload on a shorter period or use sample prefix. eg: with sample 0.1, it reload with 10% of random sample data.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1) You can create a QVD-layer and use them without reloading from sources more than necessary. Loading from QVDs compared to accessing a SQL source can be often up to 20x faster.
2) Make use of the BUFFER prefix for LOAD statements which is very good for development. It will make use of and create QVDs automatically for you employing a caching mechanism.
3) Separate the load script from the UI by having two QVWs. QVW #1 contains the entire loadscript and QVW#2 has a BINARY load in the load script. While developing you can add stuff to the load script in QVW#2 and modify the UI there too. As the new things in the load script matures and getting bug free and tested you move those parts over to QVW #1 at regular intervals.It will make incremental development of the load script and the reloads faster and every now and then you will have to move script and then reload QVW#1 but not so often.
Load a QVW data model by BINARY is even faster than loading from QVDs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Are there some other ways? What do we need to be careful about? Which transformations are bad? etc. etc.
If there is a list somewhere, please refer me.
Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
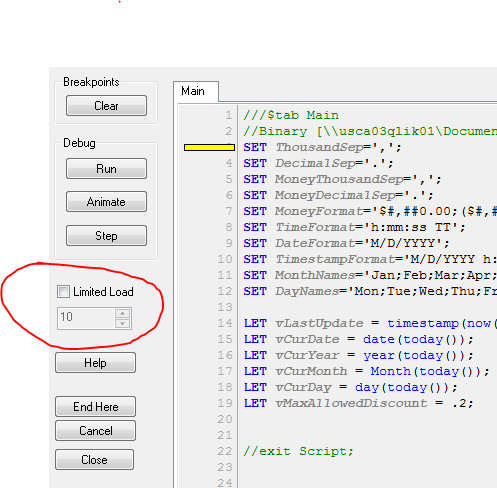
Use the Debug to reload data instead of the Reload button.
In the Debug, select how many records you want to load, check the Limit Load box and Qlik (click) Run,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think the most important facts are already mentioned by the others especially using qvd's with reduced and fixed datasets because many parts of the development and testings don't need data-updates.
This meant you need to use a multi-tier data-architecture and updating the data and changes within the script could be speed up with incremental load-approaches whereby you might need to apply incremental loadings not only for pulling the raw-data else by following (and heavy) transformation-steps, too.
Here you will find many valuable links to this: Advanced topics for creating a qlik datamodel
Further if possible try to avoid aggregation-loads, joins and nested if-constructions and in general trying to develop the datamodel in the direction of a star-scheme - it's not necessary the fastest option for the load-times but it's often the best compromize for the overall requirements.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I often use the first prefix when I need to check the syntax of the script