Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- IF statement on same value
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
IF statement on same value
I have the same Prog_Id as seen in the example below:
| UKCountry | Prog_Id | Rating | Date | Projection |
| UK | 10 | 01/05/2014 | 1,401,000 | |
| UK | 5478 | 11 | 11/10/2013 | 57,340,162 |
| UK | 5539 | 11 | 01/11/2013 | 9,103,812 |
| UK | 5560 | 11 | 25/09/2013 | 20,491,000 |
| UK | 5634 | 11 | 04/12/2013 | 27,411,600 |
| UK | 5634 | 8 | 04/12/2013 | 1,106,809 |
| UK | 5657 | 10 | 14/02/2014 | 6,476,215 |
| UK | 5665 | 10 | 26/03/2014 | 12,600,000 |
| UK | 5665 | 8 | 26/03/2014 | 2,140,016 |
| UK | 5669 | 10 | 09/05/2014 | 22,785,308 |
The difference is that it holds different rating values.
| Country | Prog_Id | Rating | Date | Projection |
| UK | 5634 | 11 | 04/12/2013 | 27,411,600 |
| UK | 5634 | 8 | 04/12/2013 | 1,106,809 |
So for example Prog_Id 5634 has the rating 11 and 8. But I want to filter this in the following manner:
If Prog_Id's are the same and IF the rating is > 10, then give me the projection value, IF NOT, give me blank.
- Tags:
- new_to_qlikview
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Keep Prog_Id in the dimension and
Try
If(rating>10,Projection,'')
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So how does this equation know and differentiate that the prog_id is the same?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In this case you are not grouping on the Prog_id so it checks the condition for each row. Hence it will check only for the rating not for the prog_id.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
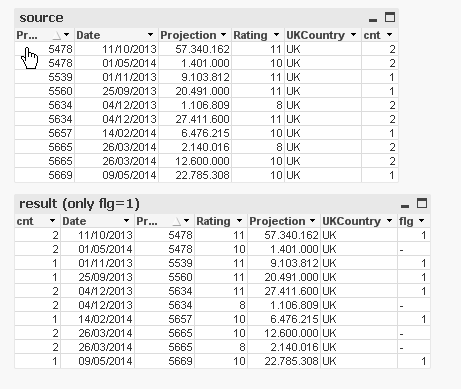
script
source:
load * inline [
UKCountry, Prog_Id, Rating, Date, Projection
UK, 5478, 10, 01/05/2014, 1401000
UK, 5478, 11, 11/10/2013, 57340162
UK, 5539, 11, 01/11/2013, 9103812
UK, 5560, 11, 25/09/2013, 20491000
UK, 5634, 11, 04/12/2013, 27411600
UK, 5634, 8, 04/12/2013, 1106809
UK, 5657, 10, 14/02/2014, 6476215
UK, 5665, 10, 26/03/2014, 12600000
UK, 5665, 8, 26/03/2014, 2140016
UK, 5669, 10, 09/05/2014, 22785308
];
left join (source) load
Prog_Id, count(Prog_Id) as cnt resident source group by Prog_Id;
result:
NoConcatenate load
*,
if(cnt = 1 or (cnt >1 and Peek(Prog_Id) <> Prog_Id and Rating > 10),1,0) as flg
Resident source
order by Prog_Id, Rating desc;