Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Join Question - Eliminate Duplicate Values in Sum
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Join Question - Eliminate Duplicate Values in Sum
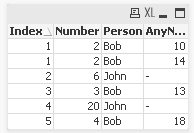
Quick (I hope) question. For the load script below, I need to join 2 tables and have the value in "Number" NOT get duplicated. Is there a way to do this?
Currently the Number column gets duplicated for due whenever there is more than 1 row in the second table.
Desired results would be for there to only be one number 2 on Bob, index 1, instead of two number 2's as in the results below. So in an expression, I need to sum the distinct Number column, which works if you incorporate Index somehow, so maybe the answer is the somehow write the sum to include Index without altering the output of the expression?
Attached is this test scenario. Hope this is easy.
Thanks much!

- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well the aggr does work.....but running into the same issue I have had using it in the past, it is so darn slow. Would work great on thousands of rows, but I am working with tens of millions of rows so it just doesn't perform fast enough on the front end. I suppose I could load it in the script, but there are a lot of numbers that are impacted so many columns would need to have the aggr run against them, not very elegant.
Thanks for the suggestions though, probably back to the drawing board on the schema.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What are these index issues you were running into (in other words: what is the join really needed for)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is the structure, the index with the same name as the table is the primary key (SQL) in each table, the rest foreign keys. (hope you aren't sorry you asked!  )
)
Table1
Table1Index
Table6Index
Table7Index
Table2
Table2Index
Table1Index
Table5Index
Table3
Table3Index
Table6Index
Table7Index
Table4
Table4Index
Table3Index
Table5Index
Table5
Table5Index
Table6Index
Table6
Table6Index
Table7Index
Table7
Table7Index
Tables 1-5 are data tables, 6 and 7 are fact tables. I was attempting to join table 1 to 2 and table 3 to 4 to get around an issue I was having with the key table getting too big and never completing the load.
- « Previous Replies
-
- 1
- 2
- Next Replies »