Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Overlapping intervals
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Overlapping intervals
Hello,
I am still face up a problem while removing overlapping intervals.
The data:
| Client | Product | From | To |
| A | A | 2015.01.01 | 2015.01.15 |
| A | A | 2015.01.15 | 2015.01.15 |
| A | A | 2015.01.10 | 2015.01.20 |
| A | A | 2015.02.01 | 2015.02.10 |
| B | B | 2015.01.01 | 2015.01.10 |
| B | B | 2015.01.15 | 2015.01.20 |
| B | B | 2015.01.13 | 2015.01.13 |
| B | B | 2015.01.13 | 2015.01.15 |
| B | C | 2015.01.01 | 2015.01.30 |
| B | C | 2015.01.10 | 2015.02.15 |
| B | C | 2015.02.20 | 2015.02.25 |
| B | C | 2015.02.19 | 2015.02.21 |
| B | C | 2015.02.23 | 2015.02.26 |
The result should be:
| Client | Product | From | To |
| A | A | 2015.01.01 | 2015.01.20 |
| A | A | 2015.02.01 | 2015.02.10 |
| B | B | 2015.01.01 | 2015.01.10 |
| B | B | 2015.01.13 | 2015.01.20 |
| B | C | 2015.01.01 | 2015.02.15 |
| B | C | 2015.02.19 | 2015.02.26 |
I need to remove overlapping intervals depending on Client and Product fields.
Thank you for your help!
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
An other way is it to loop over the distinct intervals until they are clean. So it will not produce millions of discrete rows, but it will needs 4 up to 6 loops to get the clean intervals. But try it.
INPUTTAB:
LOAD
Hash128(Client,Product,From,To) as Key0,
*
;
LOAD * INLINE [
Client Product From To
A A 2015.01.01 2015.01.15
...
](delimiter is '\t');
LOOPTAB:
LOAD Distinct
Key0,
AutoNumber(Hash128(Client,Product),'Key') as Key,
num(From) as From#,
num(To) as To#
Resident INPUTTAB;
DROP Fields From,To;
let nor1=NoOfRows('LOOPTAB');
for i= 1 to 100
Trace *** Loop $(i) ***;
let h=i-1;
TEMP:
NoConcatenate
LOAD
Hash128(Key,From#,To#) as Key$(i),
*
;
LOAD
Key$(h),
Key,
If(Key=Previous(Key) and From#>=Previous(From#) and From#-1<=Previous(To#),Previous(From#),From#) as From#,
If(Key=Previous(Key) and To#<=Previous(To#) and To#>=Previous(From#),Previous(To#),To#) as To#
Resident LOOPTAB
Order By Key,From#,To# desc;
DROP Table LOOPTAB;
LOOPTAB:
LOAD Distinct
Key$(i),
Key,
From#,
To#
Resident TEMP;
let nor2=NoOfRows('LOOPTAB');
if nor1=nor2 then
Left Join(INPUTTAB)
LOAD
Key$(h),
Date(From#) as From,
Date(To#) as To
Resident TEMP;
DROP Field Key$(h);
DROP Tables TEMP,LOOPTAB;
EXIT For;
else
Left Join(INPUTTAB)
LOAD
Key$(h),
Key$(i)
Resident TEMP;
DROP Field Key$(h);
DROP Table TEMP;
set nor1=$(nor2);
end if;
next
OUTPUTTAB:
NoConcatenate
LOAD Distinct * Resident INPUTTAB;
DROP Table INPUTTAB;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Using While it creates 500 million rows and get stuck.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
maxgro did help in my other thread Unique intervals and the solution works great on one Client and one Product. Unfortunately, I have spend a reasonable amount of time trying to transform the script that suits for many Clients and Products but with no result. Would you might checking the script?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Checking
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
May be with these modifications
tmp:
LOAD Product,
From,
To,
Client
FROM Data.xls
(biff, embedded labels, table is Sheet1$);
tmp2:
LOAD *,
if(Product = Previous(Product) and Client = Previous(Client) and From = Peek('LastFrom') and To >= Peek('LastFrom') and To <= Peek('LastTo'), 'Remove', 'Leave') as Status,
if(Product = Previous(Product) and Client = Previous(Client) and From = Peek('LastFrom') and To >= Peek('LastFrom') and To <= Peek('LastTo'), Peek('LastFrom'), From) as LastFrom,
if(Product = Previous(Product) and Client = Previous(Client) and From = Peek('LastFrom') and To >= Peek('LastFrom') and To <= Peek('LastTo'), Peek('LastTo'), To) as LastTo
Resident tmp
Order By Client, Product, From desc, To desc;
DROP Table tmp;
tmp3:
NoConcatenate
LOAD Product, From, To, Client,
if(Product = Previous(Product) and Client = Previous(Client) and From >= Peek('LastFrom') and From <= Peek('LastTo') or To >= Peek('LastFrom') and To <= Peek('LastTo') or Status='Remove', 'Remove', 'Leave') as Status,
if(Product = Previous(Product) and Client = Previous(Client) and From >= Peek('LastFrom') and From <= Peek('LastTo') or To >= Peek('LastFrom') and To <= Peek('LastTo') or Status='Remove', Peek('LastFrom'), From) as LastFrom,
if(Product = Previous(Product) and Client = Previous(Client) and From >= Peek('LastFrom') and From <= Peek('LastTo') or To >= Peek('LastFrom') and To <= Peek('LastTo') or Status='Remove', Peek('LastTo'), To) as LastTo
Resident tmp2
Order By Client, Product, From, To;
DROP Table tmp2;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I tried for a different method by identifying overlapping intervals using the intervalmatch prefix and then clustering those intervals using the hierarchy prefix.
Although the result is a bit lengthy and not performing as well as hoped, I want to post it nevertheless:
tabInput:
LOAD RecNo() as ID,
AutoNumberHash128(Client,Product) as ClntProdID,
From as Date, *
FROM [https://community.qlik.com/thread/244866] (html, codepage is 1252, embedded labels, table is @1);
tabIntervals:
IntervalMatch (Date, ClntProdID)
LOAD From,
To,
ClntProdID
Resident tabInput;
Left Join (tabIntervals)
LOAD From,
To,
ClntProdID,
ID as ParentID
Resident tabInput;
Left Join (tabIntervals)
LOAD Date,
ClntProdID,
ID
Resident tabInput;
Left Join (tabIntervals)
LOAD ID,
Min(From) as MinFrom
Resident tabIntervals
Group By ID;
Left Join (tabInput)
LOAD ID,
Min(ParentID) as ParentID
Resident tabIntervals
Where From = MinFrom
Group By ID;
DROP Table tabIntervals;
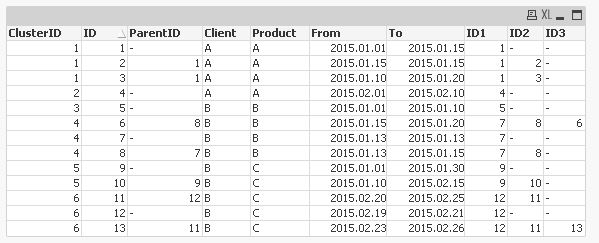
tabOutput:
Hierarchy (ChildID, ParentID, ID)
LOAD Client,
Product,
From,
To,
ID,
ID as ChildID,
ParentID
Resident tabInput;
DROP Table tabInput;
Left Join (tabOutput)
LOAD Distinct
ID1,
AutoNumber(ID1) as ClusterID
Resident tabOutput;
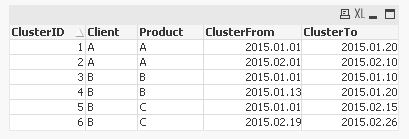
tabClusters:
LOAD ClusterID,
Date(Min(From)) as ClusterFrom,
Date(Max(To)) as ClusterTo
Resident tabOutput
Group By ClusterID;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @MarcoWedel
Your apporach (with a few adjustments) works for me.
I'd the same problem witk overlappings time periods and I've gone mad looking for a solution.
The post marked as solution on this thread doesn't work. But yours does.
Unfortunatelly I cannot mark your post as a solution.
Thank you.
Best regards,
Alonso Torres.
- « Previous Replies
-
- 1
- 2
- Next Replies »