Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Reducing load size of script
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Reducing load size of script
Hi All
I have a problem which i hope you can shed some light on.
I also have attached an example of the source information i am trying to upload.
I have two files which I am loading into my script. They both relate to each other using a unique ID.
File 1 will has unique ID codes and some informative information.
File 2 has all the payments relating to ID codes.
Now there are about 700,000 unique ID's in File 1 and about 2.5 million payments relating to those 700,000 in File 2.
I am linking the two on a the ID code however in my dashboard i don't use ID anywhere. I just use it to create the link so I can use other fields in both.
as you can imagine this make my load long and the size of my file large.
My question is can i create the link somehow and not have ID's brought into my load.
Feel free to ask more questions if i have not explained it well.
Here is a picture of my Table join as as i said attached is a sample of what the two files look like.
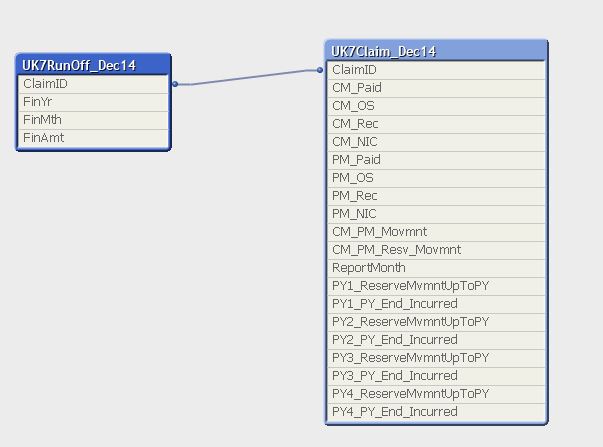
Here is my Script
LOAD ID,
CM_Paid,
CM_OS,
CM_Rec,
CM_NIC,
PM_Paid,
PM_OS,
PM_Rec,
PM_NIC,
CM_PM_Movmnt,
CM_PM_Resv_Movmnt,
ReportMonth,
PY1_ReserveMvmntUpToPY,
PY1_PY_End_Incurred,
PY2_ReserveMvmntUpToPY,
PY2_PY_End_Incurred,
PY3_ReserveMvmntUpToPY,
PY3_PY_End_Incurred,
PY4_ReserveMvmntUpToPY,
PY4_PY_End_Incurred
FROM
(txt, utf8, embedded labels, delimiter is '\t', msq, no eof);
LOAD ID,
FinYr,
FinMth,
FinAmt
FROM
(txt, utf8, embedded labels, delimiter is '\t', msq, no eof);
Any help would be much appreciated.
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, Both good answers and both seem to run in my script and reduce the size. However they are bringing me back the correct data. I dont know why but when i test it im getting the wrong amounts.
To explain which way i need it a bit better below is an example of what way i would need my final table.
File 1 claim ID is 12345 and it shows all the description info and financials which tell me what each ID total incurred was at the start of every year.
Now in File 2 claim ID 12345 may be in this file multiple times as it show payments on that ID over a four year period so as below
Claim ID Fin Mth Fin Yr Fin Amt
12345 2 2011 £250
12345 5 2011 £350
12345 9 2011 £150
12345 7 2012 £450
12345 3 2013 £550
12345 1 2014 £250
So my plan would be to use file 1 to identify Claim ID (12345) then to tell me what the incurred was at the start of 2011
I then use file 2's payment info to look at the running total over 12 months.
So Eg Incurred at start of 2011 is £100
Yr Inc Mth 1 2 3 4 5 6 7 8 9 10 11 12
2011 £100 £100 £350 £350 £350 £700 £700 £700 £700 £850 £850 £850 £850
The way i have this previously set up and working is.
I set up variables in the script which look into file 1 and identify the start of year figures .
Then when i get to my graph i divide the sum of the FinAmt from file 2 by the variable(start of year figures) from file 1.
I then plot this by month on the graph which shows me the run off of a particular years. Each year has its own line.
No that you know the back round you might be help.
So the problem now is if I use apply map or join they dont seem to match up...
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't see enough of the data to be sure, but it sounds like it may be difficult to join and get the correct results. Have you considered using leaving as two tables and using autonumber() on the ClaimID field to reduce it's size?
-Rob
- « Previous Replies
-
- 1
- 2
- Next Replies »