Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Removing duplicate values in field during load
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Removing duplicate values in field during load
I have a csv file with two columns
| NAME | STATE |
| John Doe | NC, AL, CA, CA |
| Jim Smith | SC |
| Jane Doe | AR, NY |
| Jake Sparow | AL, GA, MS |
some users have duplicate values in the STATE field. How can eliminate the duplicate values during the load.
| NAME | STATE |
| John Doe | NC, AL, CA |
| Jim Smith | SC |
| Jane Doe | AR, NY |
| Jake Sparow | AL, GA, MS |
CA is just an example it could be any state, and multiple duplicates. End result just needs to be one state for every state represented.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You need to adapt the limiter ',' to the one used: ';', then it works just fine:
STATES:
LOAD [USER ID], Concat(DISTINCT SubSTATE,'; ') as [LICENSE STATES]
GROUP BY [USER ID];
LOAD [USER ID], Trim(Subfield( [LICENSE STATES], ';')) as SubSTATE;
LOAD [USER ID],
[LICENSE STATES]
FROM
[States.xlsx]
(ooxml, embedded labels, table is Tabelle1);
| USER ID | LICENSE STATES |
|---|---|
| 168644 | AR; AZ; CT; IL; MI; NC; NM; SC; TN; TX; VA; WV |
| 229438 | CA |
| 685237 | IL |
| 695742 | CO; FL; GA; IA; IL; IN; KY; MI; NC; NY; OH; PA; SC; TN; TX; VA |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can split your STATE value substrings, creating a record per state, then aggregating using a distinct concat:
LOAD NAME, Concat(DISTINCT SubSTATE,', ') as STATE
GROUP BY NAME;
LOAD NAME, Trim(Subfield(STATE, ',')) as SubSTATE;
LOAD * INLINE [
NAME STATE
John Doe NC, AL, CA, CA
Jim Smith SC
Jane Doe AR, NY
Jake Sparow AL, GA, MS
] (delimiter is '\t');
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello, Melvin!
You can also use a secret ability of a SubField() function! Just omit the third parameter of it when load. Like this:
LOAD DISTINCT
NAME,
Subfield(STATE,', ') as STATE
...
It will create a loop where all comma-separated values will be... separate for rows:
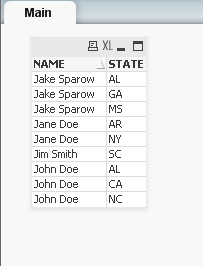
Yes, the states will be in his own row and names are duplicated, but it can be more usefull in backend!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am not able to get this to work here is my script to load all the data.
LOAD [USER ID],
[LICENSE STATES]
FROM
(ooxml, embedded labels, table is USER);
and a snap of my data
| USER ID | LICENSE STATES |
| 168644 | AR;AR;AZ;CT;IL;MI;NC;NM;SC;TN;TX;VA;WV |
| 229438 | CA;CA;CA |
| 695742 | CO;FL;FL;GA;IA;IL;IN;KY;MI;NC;NY;OH;PA;SC;TN;TX;VA |
| 685237 | IL;IL |
I need to remove the duplicate states in each cell
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am not able to get this to work here is my script to load all the data.
LOAD [USER ID],
[LICENSE STATES]
FROM
(ooxml, embedded labels, table is USER);
and a snap of my data
| USER ID | LICENSE STATES |
| 168644 | AR;AR;AZ;CT;IL;MI;NC;NM;SC;TN;TX;VA;WV |
| 229438 | CA;CA;CA |
| 695742 | CO;FL;FL;GA;IA;IL;IN;KY;MI;NC;NY;OH;PA;SC;TN;TX;VA |
| 685237 | IL;IL |
I need to remove the duplicate states in each cell
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You need to adapt the limiter ',' to the one used: ';', then it works just fine:
STATES:
LOAD [USER ID], Concat(DISTINCT SubSTATE,'; ') as [LICENSE STATES]
GROUP BY [USER ID];
LOAD [USER ID], Trim(Subfield( [LICENSE STATES], ';')) as SubSTATE;
LOAD [USER ID],
[LICENSE STATES]
FROM
[States.xlsx]
(ooxml, embedded labels, table is Tabelle1);
| USER ID | LICENSE STATES |
|---|---|
| 168644 | AR; AZ; CT; IL; MI; NC; NM; SC; TN; TX; VA; WV |
| 229438 | CA |
| 685237 | IL |
| 695742 | CO; FL; GA; IA; IL; IN; KY; MI; NC; NY; OH; PA; SC; TN; TX; VA |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
On a different note. Would there be a way to just identify the license states cells that have duplicate values and have them highlighted in a table object as apposed to removing the duplicates during the load.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Shoudl be possible:
STATES:
LOAD *,
If(SubStringCount([LICENSE STATES],';') <> SubStringCount([LICENSE STATES DEDUP],';'), 1,0) as Flag;
LOAD [USER ID],[LICENSE STATES], Concat(DISTINCT SubSTATE,'; ') as [LICENSE STATES DEDUP]
GROUP BY [USER ID], [LICENSE STATES];
LOAD [USER ID],[LICENSE STATES], Trim(Subfield( [LICENSE STATES], ';')) as SubSTATE;
LOAD [USER ID],
[LICENSE STATES]
FROM
[States.xlsx]
(ooxml, embedded labels, table is Tabelle1);
| USER ID | LICENSE STATES | Flag | LICENSE STATES DEDUP |
|---|---|---|---|
| 12345 | FL;TX | 0 | FL; TX |
| 168644 | AR;AR;AZ;CT;IL;MI;NC;NM;SC;TN;TX;VA;WV | 1 | AR; AZ; CT; IL; MI; NC; NM; SC; TN; TX; VA; WV |
| 229438 | CA;CA;CA | 1 | CA |
| 685237 | IL;IL | 1 | IL |
| 695742 | CO;FL;FL;GA;IA;IL;IN;KY;MI;NC;NY;OH;PA;SC;TN;TX;VA | 1 | CO; FL; GA; IA; IL; IN; KY; MI; NC; NY; OH; PA; SC; TN; TX; VA |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
just to add a possible front end solution:

=Concat(DISTINCT Trim(SubField([LICENSE STATES],';',ValueLoop(1,Max(TOTAL SubStringCount([LICENSE STATES],';'))+1))),';')
(I think you should go with Stefan's script based approach though.)
hope this helps
regards
Marco