Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- Equipment Utilization by Hour
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Equipment Utilization by Hour
Hi,
I am looking to determine the utilization of equipment by hour. I have created hour buckets and can use IntervalMatch to get the sum of the SecondsUsed based on start time, but what do I do if the SecondsUsed runs over into the next bucket? Are buckets the wrong approach for this? My main goal is to determine the busiest periods based on utilization. A bonus would be to determine how often all 4 machines are in use...
Take, for example, the first row from my data below:
StartTimestamp: 2015-11-01 00:59:51.000
SecondsUsed: 24
ItemID: 2
Therefore the usage for that one record should be split between two buckets:
Bucket: 1
StartTime: 2015-11-01 00:00:00
EndTime: 2015-11-01 00:59:59
Usage: 9 seconds
Bucket: 2
StartTime: 2015-11-01 01:00:00
EndTime: 2015-11-01 01:59:59
Usage: 15 seconds
Here is an example of the raw utilization data that I have:
Fact:
LOAD * INLINE [
StartTimestamp, SecondsUsed, ItemID
2015-11-01 00:59:51.000, 24, 2
2015-11-01 00:47:40.000, 24, 3
2015-11-01 00:49:49.000, 30, 1
2015-11-01 12:50:19.000, 31, 0
2015-11-02 00:51:12.000, 30, 3
2015-11-02 12:51:53.000, 30, 1
2015-11-02 16:06:32.000, 28, 2
];
Please let me know if any more details would be helpful.
Thanks in advance for any and all help.
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jonathan,
You don't need N buckets. You need only 24 bucket for 24 hours.
So, can be solved if is created one master time table (with 1 second interval) and linked with the fact table, in order to count the number of seconds per hour / equipment, based on start time and SecondsUsed. See file attached.
Final result will be as in the table below. I think this is what you need.
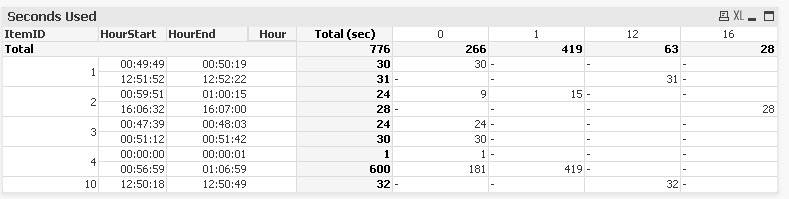
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you very much for this code. Exactly what I was hoping to achieve!
And thanks to everyone for helping out. This was my first post on the Community and I have to say it rocks. Keep up the good work.
- « Previous Replies
-
- 1
- 2
- Next Replies »