Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- Loading data based on modified file time
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Loading data based on modified file time
I've got some log files that I need to load and parse for audit purposes - that bit I can do no problem.
These files can grow very large and I have got many (scores) of Instances each creating their own log files. Unfortunately the log files do not cut-over after a set time but rather when they grow to a certain size - hence each file can have many days of activity or just a few hours or minutes.
The logs are all called: "tm1server.log". When the log becomes a certain size it will rename to "tm1server.log.1" and start a fresh log. If there's already a log called "tm1server.log.1" that log will be renamed to "tm1server.log.2" and so on, hence the higher the number appended the older the log.
i.e.
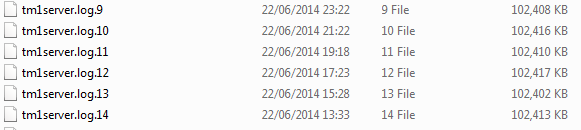
So what I want to do is on a daily basis load any file that has been updated since the start of the previous day. Then I can parse the file to keep just yesterdays data for certain entries in the files. This results in a file that is just kb in size even though I'm potentially loading 10's of GB.
Because of the poor naming convention and the way the files cut-over (based on size not date) the only way I can think to limit what I load is based on filetime(). I have written this script:
For each Instance in 'alm-2u', 'cmac_inv-1u', 'cmac_scs-1u', 'cobam-1u', 'ddc-2u', 'ddc-3u', 'finrecharge-1u', 'gbl-1u', 'gbm_bt-1u', 'gbm-1u'
For each tm1serverlog in '\\GBW04804\UAT_Instance\$(Instance)\log\tm1server.log*'
recent_logs:
LOAD *,
FROM
$(tm1serverlog)
(txt, utf8, no labels, delimiter is ',', msq)
WHERE Date(filetime(), 'DD/MM/YYYY') >= today()-1;
next tm1serverlog
next Instance
Now this is a test script based on just 10 Instances and I've got scores. For just a couple of weeks data it's taking 35 minutes to reload due to the number and size of logs. Long term it's not practical to load all logs every day. Unfortunately the above script although works does not improve load times because QlikView seems to open and load the file before it evaluates the filetime() hence it loads every file instead of simply disregarding the older files before load.
Is it possible to totally ignore files based on when they are modified? i.e. So QlikView does not have to load the entire file before it disregards it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You meant TM1 did a rename from all log-files each time there is a new one - possibly thousands of files every xx minutes? There are none better settings possible?
I think you are right with the assumption that qv always evaluates the complete load-statement and file-functions like filetime() didn't look from outside on a file. But in my experience is this quite fast if you only load one row:
FileTimeLog:
First 1
Load *, filename() as FileName, filetime() as FileTime From xyz;
You could use these FileTimeLog to identify those logs which aren't loaded.
Another possibility could be to move each log-file after reload to another folder so that you have only the newest log-files in your log-file-folder. If you can't or don't want to move the log-files you could copy them and make before the load a synchronization with robocopy in a special load-folder.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marcus, yes that's correct. The functionality around the TM1 logs is really poor, we've got enhancement requests with IBM but it's not likely to result in anything soon.
The problem with using First 1 would be that I get a list of files, but in the time it takes to do that and then do a full load of that list of files is that some could have been renamed in the meantime. Ergo the "tm1server.log.1" file I'm loading could actually have been called "tm1server.log" a few minutes before and the "tm1server.log.1" I was hoping to load has been renamed to "tm1server.log.2" and is missed off my load.
I'll consider the moving option but not sure if other constraints will prevent me from being able to do that. Thanks for your suggestions though.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I tried the First 1 option and that does indeed run in a matter of seconds. So perhaps if I schedule the reloads for when the logs are not going to be written to I can use this option. So I've written this script:
for each Instance in DirList('\\GBW04804\UAT_Instance\*')
for each tm1serverlog in FileList('$(Instance)\log\tm1server.log*')
all_log_names:
First 1
LOAD @1,
Date(filetime(), 'DD/MM/YYYY') as ModTimeStamp,
'$(tm1serverlog)' as logfilename
FROM
$(tm1serverlog)
(txt, utf8, no labels, delimiter is ',', msq);
next tm1serverlog
next Instance
recent_logs_names:
LOAD ModTimeStamp,
logfilename
Resident all_log_names
WHERE ModTimeStamp >= today()-1;
drop table all_log_names;
So I've got a field with a list of all the logs I want to reload. i.e.
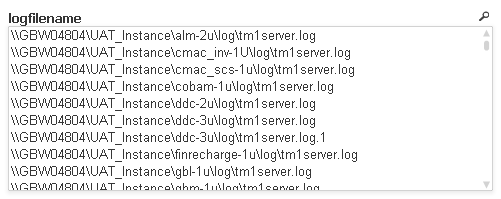
...but how do I use the values in that field to do a full load of those logs listed?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ignore the last post I think I've found the answer in Henric Cronström blog:
http://community.qlik.com/blogs/qlikviewdesignblog/2013/09/02/loops-in-the-script
i.e.
For vFileNo = 1 to NoOfRows('recent_logs_names')
Let vFileName = Peek('logfilename',vFileNo-1,'recent_logs_names');
Load @1,
'$(vFileName)' as logfilename
From [$(vFileName)]
(txt, utf8, no labels, delimiter is ',', msq);
Next vFileNo
nb I got the load time to just under 2 1/2 minutes, but that was searching ALL log files not just the sample 10.