Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics & AI
- :
- Products & Topics
- :
- Visualization and Usability
- :
- Script Process Question
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Script Process Question
I am attempting to do an incremental load with my source data.
The data is route data for our trucks that is uploaded from hand helds. The problem is that there are a number of scenarios where an upload doesn't happen on time and might happen the next day for example.
It was suggested that I check my date field for 2 days prior to make sure that I get all of the data.
So the code I am trying is this:
Let vPriorDate = date(now()-2);
StopData:
LOAD * ;
SQL SELECT *
from SourceData
WHERE Route_Date >= '$(vPriorDate)'
And Branch < '800';
// COMBINE NEW DATA WITH EXISTING QVD
CONCATENATE (StopData)
LOAD *
FROM [lib://QVDS/DTRAK\Load\StopData2017.QVD] (QVD);
// STORE THE COMBINED TABLE BACK TO QVD
Store StopData into [lib://QVDS/DTRAK\Load\StopData2017.QVD](qvd);
Drop Table StopData;
The result of this load should be every route that was run going two days back.
I then want to read my existing QVD and concatenate the new data with this QVD.
Repeat this process each day.
Since I am going 2 days back I will pull some of the same data multiple times and concatenating it with my QVD.
How do I make sure that I am not loading duplicate data into my QVD?
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you have a unique Key (an ID for example):
Maybe you should alter your code as follow:
Let vPriorDate = date(now()-2);
StopData:
LOAD * ;
SQL SELECT *
from SourceData
WHERE Route_Date >= '$(vPriorDate)'
And Branch < '800';
// COMBINE NEW DATA WITH EXISTING QVD
CONCATENATE (StopData)
LOAD *
FROM [lib://QVDS/DTRAK\Load\StopData2017.QVD] (QVD)
WHERE NOT EXISTS(ID)
;
// STORE THE COMBINED TABLE BACK TO QVD
Store StopData into [lib://QVDS/DTRAK\Load\StopData2017.QVD](qvd);
Drop Table StopData;
For more informations, please refer to these:
https://www.resultdata.com/three-types-of-qlikview-incremental-loads/
Here are the 3 incremental load methods:
1. Insert Only:
Let us say, we have sales raw data (in Excel) and whenever a new sales get registered, it is updated with basic details about the sale by modified date. Since, we are working on QVDs, we already have QVD created till yesterday (25-Aug-14 in this case). Now, I want to load only the incremental records (Highlighted in yellow below).
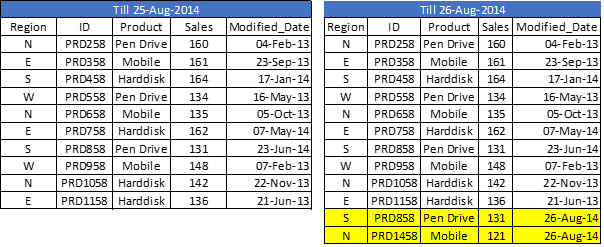
To perform this exercise, first create a QVD for data till 25-Aug-14. To identify new incremental records, we need to know the date till which, QVD is already updated. This can be identified by checking the maximum of Modified_date in available QVD file.
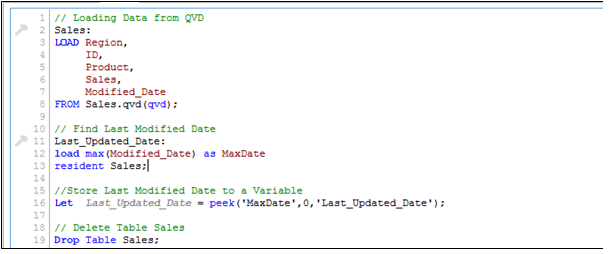
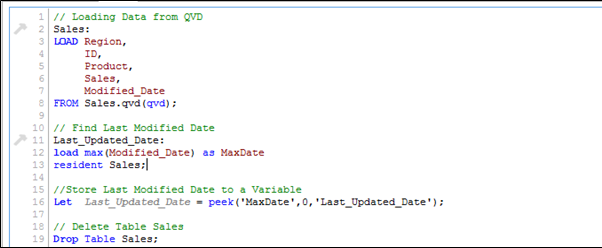
As mentioned before, I have assumed that “Sales. qvd” is updated with data till 25-Aug-14. In order to identify the last modified date of “Sales. qvd”, following code can help:
{kind=link}
Here, I have loaded the last updated QVD into the memory and then identified the last modified date by storing maximum of “Modified_Date”. Next we store this date in a variable “Last_Updated_Date” and drop the table “Sales”. In above code, I have used Peek() function to store maximum of modified date. Here is it’s syntax:
Peek( FieldName, Row Number, TableName)
This function returns the contents of given field for a specified row from the internal table. FieldName and TableName must be given as a string and Row must be an integer. 0 denotes the first record, 1 the second and so on. Negative numbers indicate order from the end of the table. -1 denotes the last record.
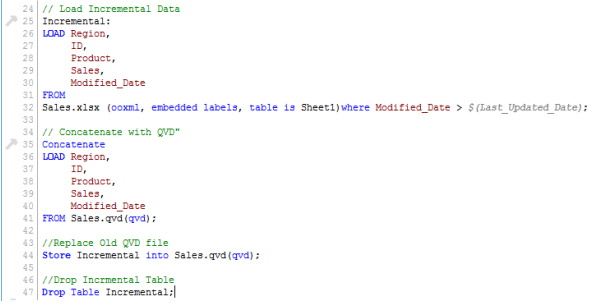
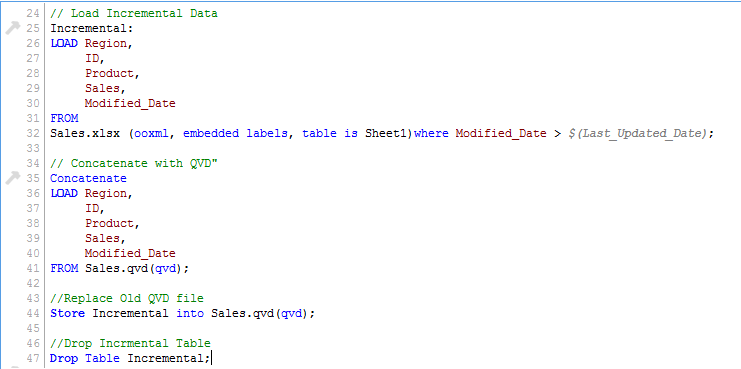
Since we know the date after which the records will be considered as new records, we can Load incremental records of the data set (Where clause in Load statement) and merge them with available QVD (Look at the snapshot below).
{kind=link}
Now, load updated QVD (Sales), it would have incremental records.
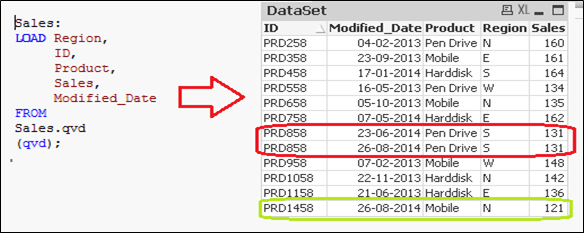
As you can see, two records of 26-Aug-14 were added. However, we have inserted a duplicate record also. Now we can say that, an INSERT only method does not validate for duplicate records because we have not accessed the available records.
Also, in this method we cannot update value of existing records.
To summarize, following are the steps to load only the incremental records to QVD using INSERT only method:
1) Identify New Records and Load it
2) Concatenate this data with QVD file
3) Replace old QVD file with new concatenated table
2. Insert and Update method:
As seen in previous example, we are not able to perform check for duplicate records and update existing record. This is where, Insert and Update method comes to help:
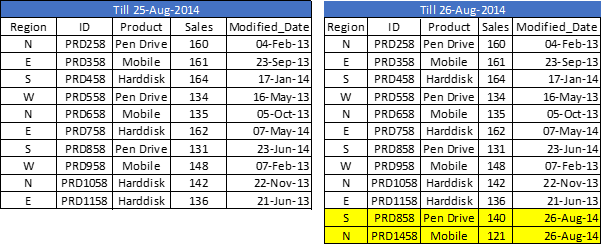
In the data set above (Right table), we have one record (ID = PRD1458) to add and another one (ID = PRD858) to update (value of sales from 131 to 140). Now, to update and check for duplicate records, we need a primary key in our data set.
Let’s assume that ID is the primary key and based on modification date and ID, we should be able to identify & classify the new or modified records.
In order to execute this method, follow similar steps to identify the new records as we have done in INSERT only method and while concatenating incremental data with existing one, we apply the check for duplicated records or update the value of existing records.

Here, we have loaded only those records where Primary Key(ID) is new and use of Exists() function stops the QVD from loading the outdated records since the UPDATED version is currently in memory so values of existing records gets updated automatically.
Now, we have all unique records available in QVD with an updated sales value for ID(PRD858).
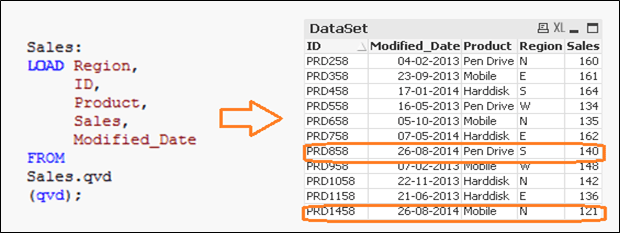
3. INSERT, UPDATE, & DELETE method:
The Script for this method is very similar to the INSERT & UPDATE, however here we have an additional step needed to remove deleted records.
We will load primary keys of all records from current data set and apply an inner join with concatenated data set (Old+Incremental). Inner join will retain only common records and therefore delete unwanted records. Let’s assume that we want to delete a record of (ID PRD1058) in the previous example.
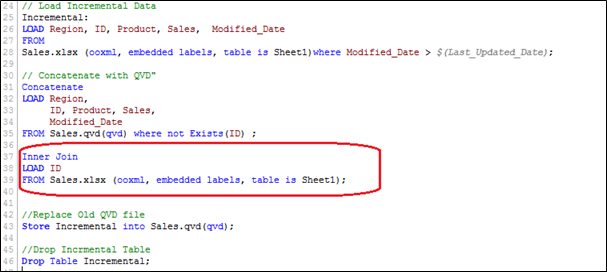
Here, we have a data set with the addition of one record (ID PRD1458), modification of one record (ID PRD158) and deletion of one record (ID PRD1058).

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you have a unique Key (an ID for example):
Maybe you should alter your code as follow:
Let vPriorDate = date(now()-2);
StopData:
LOAD * ;
SQL SELECT *
from SourceData
WHERE Route_Date >= '$(vPriorDate)'
And Branch < '800';
// COMBINE NEW DATA WITH EXISTING QVD
CONCATENATE (StopData)
LOAD *
FROM [lib://QVDS/DTRAK\Load\StopData2017.QVD] (QVD)
WHERE NOT EXISTS(ID)
;
// STORE THE COMBINED TABLE BACK TO QVD
Store StopData into [lib://QVDS/DTRAK\Load\StopData2017.QVD](qvd);
Drop Table StopData;
For more informations, please refer to these:
https://www.resultdata.com/three-types-of-qlikview-incremental-loads/
Here are the 3 incremental load methods:
1. Insert Only:
Let us say, we have sales raw data (in Excel) and whenever a new sales get registered, it is updated with basic details about the sale by modified date. Since, we are working on QVDs, we already have QVD created till yesterday (25-Aug-14 in this case). Now, I want to load only the incremental records (Highlighted in yellow below).
To perform this exercise, first create a QVD for data till 25-Aug-14. To identify new incremental records, we need to know the date till which, QVD is already updated. This can be identified by checking the maximum of Modified_date in available QVD file.
As mentioned before, I have assumed that “Sales. qvd” is updated with data till 25-Aug-14. In order to identify the last modified date of “Sales. qvd”, following code can help:
Here, I have loaded the last updated QVD into the memory and then identified the last modified date by storing maximum of “Modified_Date”. Next we store this date in a variable “Last_Updated_Date” and drop the table “Sales”. In above code, I have used Peek() function to store maximum of modified date. Here is it’s syntax:
Peek( FieldName, Row Number, TableName)
This function returns the contents of given field for a specified row from the internal table. FieldName and TableName must be given as a string and Row must be an integer. 0 denotes the first record, 1 the second and so on. Negative numbers indicate order from the end of the table. -1 denotes the last record.
Since we know the date after which the records will be considered as new records, we can Load incremental records of the data set (Where clause in Load statement) and merge them with available QVD (Look at the snapshot below).
Now, load updated QVD (Sales), it would have incremental records.
As you can see, two records of 26-Aug-14 were added. However, we have inserted a duplicate record also. Now we can say that, an INSERT only method does not validate for duplicate records because we have not accessed the available records.
Also, in this method we cannot update value of existing records.
To summarize, following are the steps to load only the incremental records to QVD using INSERT only method:
1) Identify New Records and Load it
2) Concatenate this data with QVD file
3) Replace old QVD file with new concatenated table
2. Insert and Update method:
As seen in previous example, we are not able to perform check for duplicate records and update existing record. This is where, Insert and Update method comes to help:
In the data set above (Right table), we have one record (ID = PRD1458) to add and another one (ID = PRD858) to update (value of sales from 131 to 140). Now, to update and check for duplicate records, we need a primary key in our data set.
Let’s assume that ID is the primary key and based on modification date and ID, we should be able to identify & classify the new or modified records.
In order to execute this method, follow similar steps to identify the new records as we have done in INSERT only method and while concatenating incremental data with existing one, we apply the check for duplicated records or update the value of existing records.
Here, we have loaded only those records where Primary Key(ID) is new and use of Exists() function stops the QVD from loading the outdated records since the UPDATED version is currently in memory so values of existing records gets updated automatically.
Now, we have all unique records available in QVD with an updated sales value for ID(PRD858).
3. INSERT, UPDATE, & DELETE method:
The Script for this method is very similar to the INSERT & UPDATE, however here we have an additional step needed to remove deleted records.
We will load primary keys of all records from current data set and apply an inner join with concatenated data set (Old+Incremental). Inner join will retain only common records and therefore delete unwanted records. Let’s assume that we want to delete a record of (ID PRD1058) in the previous example.
Here, we have a data set with the addition of one record (ID PRD1458), modification of one record (ID PRD158) and deletion of one record (ID PRD1058).