Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- optimal design of QVD Tier structure
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
optimal design of QVD Tier structure
I am wondering what would be the best design of structuring QVD and QVW files?
I want to consider:
- Frequency of report reloads
- Ease of tracing errors
- Ease of making changes
- Performance on QV Server and database servers where we read from
I read in some posts that 2 or 3-tiers would be best. I drew out a diagram that I think would be reasonable..
If I understood the definition of tiers correctly, I believe I have 4 tiers in the diagram.
Anyone have better ideas? Or are you using a better structure?
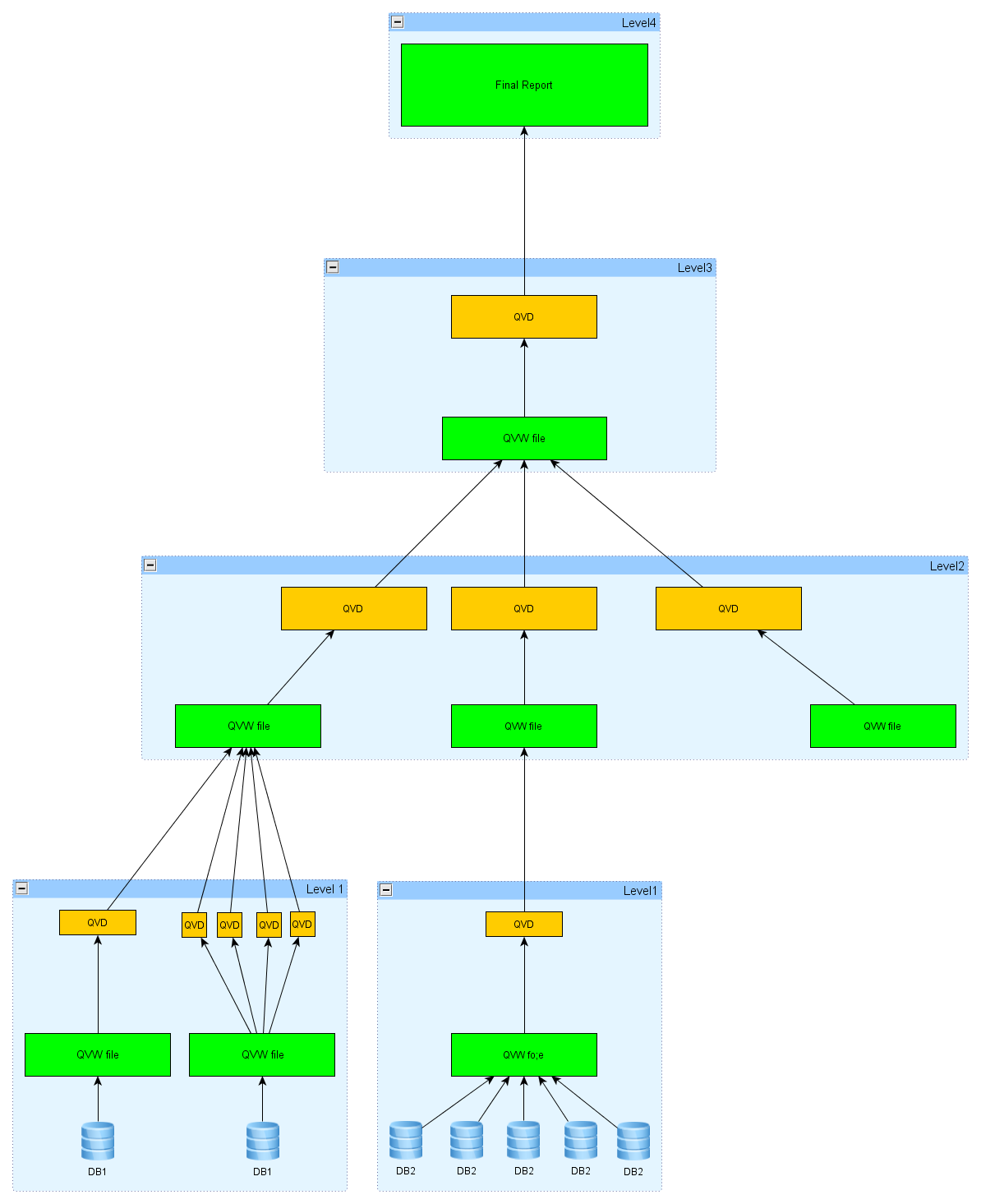
Level 1 pulls directly from databases and stores data in QVD's. Then other dashboards that need this data can re-use the QVD's instead of giving the databases too much stress. That means my dashboard will be as up to date as data from this level.
Level 2 organizes data needed specifically for the dashboard, outputs data from each datasource as a QVD. I have one qvw file for each data source.
Level 3. Pulls together the QVD's created from level 2, outputs one central QVD file. Stores some historical data as well.
Level 4. Read the central QVD, display charts and tables for the user.
Would this make it a 4-tier architecture?
I thought perhaps I can just skip level 4, and implement the final dashboard at Level 3. However, I also have to do some processing to create historical data, which is not provided in the source databases. Since I read and write to the same QVD, I decided to go one more level, so that level 4 only needs to read data and not output anything.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Theoretically, it sounds like there more structure and thought you put into your process, the better it will perform.
In reality, it often becomes counter productive to "over engineer" your structure. For example, if you have a problem with one of your dashboards, you will have to troubleshoot 4 layers of logic and perhaps a dozen of different load scripts.
It sounds like many QVD files will be shared between applications. Yes... however, except for a few "popular" tables such as "Sales", and Master Data, vast majority of your QVD files will only be used once. If you build an elaborate structure for the sake of sharing QVDs, you will "pay the price" of working with an overly complex environment every time, yet enjoy the benefits of sharing only once in a while...
My two cents would be to simplify and only make it as structured as absolutely needed...
cheers,
Oleg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Theoretically, it sounds like there more structure and thought you put into your process, the better it will perform.
In reality, it often becomes counter productive to "over engineer" your structure. For example, if you have a problem with one of your dashboards, you will have to troubleshoot 4 layers of logic and perhaps a dozen of different load scripts.
It sounds like many QVD files will be shared between applications. Yes... however, except for a few "popular" tables such as "Sales", and Master Data, vast majority of your QVD files will only be used once. If you build an elaborate structure for the sake of sharing QVDs, you will "pay the price" of working with an overly complex environment every time, yet enjoy the benefits of sharing only once in a while...
My two cents would be to simplify and only make it as structured as absolutely needed...
cheers,
Oleg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Wacao,
While your structure seems fine to me but Oleg is perfectly right, the more layers you make you will add more time in development as well as in maintenance,
also it will add more confusion.
What I follow and seen most of the developers around me follow is that
Layer 1: extract raw qvds from source tables.
Layer 2: use raw QVDs and do all scripting to get desired QVDs
Layer3: generate data model for your application (this is your final application without UI)
Layer4: use binary load from layer3 and make all the UI (Section access applied here only)
This is on a general basis and sometimes I may use one more layer or one less layer.
So, it all depends on the requirements but as I said more layers means more time to your pretty dashboard. (not always sometimes It helps also.), so keep it to minimal.
..
Ashutosh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I agree with the above two statements. When we were developing our Best Practices we were set on a three-tiered model. But after almost four years of working with QV we've settled in with two-tiers for most applications. A few are one tiered and even fewer are truly three tiered. In fact, it's not unusual to have a mixture within an application: base table QVDs, specialized QVDs that are created from base table QVDs, and direct loads from Excel, SharePoint or small SQL databases.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I see that there is no golden formula, but it does seem like over-engineering this causes lots of problems for maintenance work.
Thank you Oleg, Ashutosh and bgarland!
Cheers,
WCWC
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
I was wondering why would you recommend to use binary load from layer3? Any chance you can explain the function of binary load please.
Thanks
Max
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Maximuss,
There are multiple reason why to use binary load from the file.
1. If your user are going to download your qvw application they are not going to see any script written underneath.
This is required for security purpose of your script and to remove the complexity for users.
2. As Ashutosh explained that the layour in which you do the binary load will also contains section access logic. It is required for maintenance and security purpose. The section access tab will be kept hidden and if you need to change anything related to section access script, you don't need to run the whole datamodel script. You do the changes in section access, run it and you are ready to go rather than if you have your section access code written with your datamodel script, you need to run the whole script again. it is very time consuming. The binary load is very fast.
Regards,
Anosh Nathaniel
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am designing a 4 tier structure as described by Ashutosh Paliwal below. I
have over 100 source tables that will need to be generated into QVDs. Is there quick
way to accomplish this by looping through all tables within a schema and
storing them into one folder? If so, how do you name the tables unique names in
the store statement?
Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Does Binary load improve dashboard performance ?
Shubham