Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- [Perfect Key]?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
[Perfect Key]?
Hi all,
Please see this screenshot from my data model:
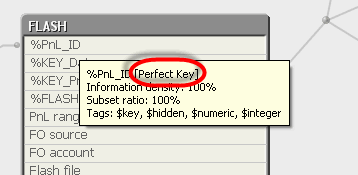
Can anyone please explain what "Perfect Key" means? Not every key has it. I do like to think my model is perfect  ...
...
Thanks,
Jason
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jason,
That means that the field is populated with 100% different unique values. That's not always the case because the key value can be more than once in the same field (for example, in a 1:n relation i. e.: invoice header - invoice details).
Hope that makes sense.
Miguel
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jason,
That means that the field is populated with 100% different unique values. That's not always the case because the key value can be more than once in the same field (for example, in a 1:n relation i. e.: invoice header - invoice details).
Hope that makes sense.
Miguel
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ah - that would make sense!
Thanks Miguel.
Jason
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Miguel,
I have not found these definitions on the reference manual, therfore I have decided to find the answer on my own, but it seems to be different from your answer.
I believe that the definition that you have given is actually the definition of [Primary Key].
The [Perfect Key] is a bit more: it is a [Primary Key] (unique) with no "orphans".
Let me clarify this with 2 examples:
Example 1)
InvoiceDetails:
LOAD *
INLINE [
InvoiceID, InvoiceLine, ProductID, Quantity, Amount
Inv001,1,PR01,10,50
Inv001,2,PR02,10,40
Inv002,1,PR01,30,150
Inv002,2,PR03,10,800
];
Invoices:
LOAD *
INLINE [
InvoiceID, ClientID
Inv001,CL0001
Inv002,CL0002
];
In this example, InvoiceID is [Key] in InvoiceDetails and [Perfect Key] in Invoices: it is unique and it has no orphans.
Example 2)
InvoiceDetails:
LOAD *
INLINE [
InvoiceID, InvoiceLine, ProductID, Quantity, Amount
Inv001,1,PR01,10,50
Inv001,2,PR02,10,40
Inv002,1,PR01,30,150
Inv002,2,PR03,10,800
Inv003,1,PR01,10,50
];
Invoices:
LOAD *
INLINE [
InvoiceID, ClientID
Inv001,CL0001
Inv002,CL0002
];
In this example, InvoiceID is [Key] in InvoiceDetails and [Primary Key] in Invoices. There is a value in InvoiceDetails, Inv003, that does not find a corresponding value in the Invoices table. This is called a "orphan". For this reason InvoiceID is not anymore perfect, but it is still primary, because it is unique.
If you copy-paste the example you can verify it
I hope that it all makes sense to you.
Jason, if you both agree, I would kindly ask you to mark this post as correct answer. this would perhaps help other developers. I have been helped a lot so far, and i would be very happy to begin to give my small contribution.
Regards
Francesco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Francesco,
Thanks for chipping in and for sharing your example.
In QlikView, once the tables have been loaded, key fields are actually ONE field (one listbox), not two fields as it happens in a relational model. In your example 2, the field InvoiceID is not 100% populated with unique values, because it has repeated values and there is no full correspondence between both tables, therefore the primary key and the key.
That's why I mentioned the 1:n relationship. Or to put my own post in different words: if the field is 100% populated with unique values, and these values have a relationship of 1:1 (in your example 1, InvoiceID), then is a perfect key, otherwise is a primary key or a key.
I don't see any differences here between what we both say, in your example 1, InvoiceID is a perfect key because all values in that field alone are unique, and the field is populated 100% in the model, isn't it?
If values are not unique, then there is not a 1:1 relationship, that means, if values are 1:n then there is no possible "unique" values, because they are not unique but repeated!
Hope this makes sense as well.
Miguel
P.S.: I'd strongly recommend you to create a Document where you explain with as much detail as possible the findings on keys, even attaching a small sample QVW, so people can download it or print it as PDF.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Miguel,
your definition of perfect key and primary key is different from the definition of Qlikview.
Please follow these steps:
1) Copy this text
InvoiceDetails:
LOAD *
INLINE [
InvoiceID, InvoiceLine, ProductID, Quantity, Amount
Inv001,1,PR01,10,50
Inv001,2,PR02,10,40
Inv002,1,PR01,30,150
Inv002,2,PR03,10,800
];
Invoices:
LOAD *
INLINE [
InvoiceID, ClientID
Inv001,CL0001
Inv002,CL0002
];
2) Paste it in a new Qlkview document, save it and run it
3) Go to the Table Editor and put the mouse on the field invoice ID of the table Invoices
4) You will notice the evidence: Qlikview says that it si a perfect key
5) Read again your phrase if the field is 100% populated with unique values, and these values have a relationship of 1:1 (in your example 1, InvoiceID), then is a perfect key, otherwise is a primary key or a key.
6) Observe the data: it is a 1:n relationship.
Now, the field invoice ID of the table Invoices is 100% populated with unique values, but it is on a 1:n relationship. Hence, according to your definition, it is a Primary Key. But according to Qliktech it is a Perfect key. Now we have just one choice: should we trust you or Qliktech?
So, I hope that it is clear now.
The definition of Perfect key is the following: A Perfect Key is a key populated with unique values, and it must have ALL the values that are in the associated fields. Or, to say the same concept in a Qlikview terminology, the Perfect key is a Primary Key with Subset Ratio = 100%.
If yo uhave time, please run also the example 2: you will notice that it's downgraded to primary key, because it does not have the value Inv003, therefore now the subset ratio is 67% (which means 2 values out of the 3 existing)
I really hope that you will correct your definitions now
Have a nice day
F.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Oh my God, I have a terrible suspect.
Miguel, please let's clarify. The relation between the 2 tables, in the example 1 (here below, again), in your opinion, is it 1:1 or is it 1:n?
Because.. if you are saying that it is 1:1, then we have a big problem 😞
InvoiceDetails:
LOAD *
INLINE [
InvoiceID, InvoiceLine, ProductID, Quantity, Amount
Inv001,1,PR01,10,50
Inv001,2,PR02,10,40
Inv002,1,PR01,30,150
Inv002,2,PR03,10,800
];
Invoices:
LOAD *
INLINE [
InvoiceID, ClientID
Inv001,CL0001
Inv002,CL0002
];
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Francesco,
Thanks for your answer.
Please find the my load script,
Invoices:
LOAD *
INLINE [
InvoiceID, ClientID
Inv001,CL0001
Inv002,CL0002
,CL0003 -> Here InvoiceID is Null
,CL0004
];
But, here showing Invoice is Perfect Key and Information density 100% and Subset ration 100%.
I have doubt, perfect key always Unique Id and Not null(Unique + Not Null) values right?
And,
InvoiceDetails:
LOAD *
INLINE [
InvoiceID, InvoiceLine, ProductID, Quantity, Amount
Inv001,1,PR01,10,50
Inv001,2,PR02,10,40
Inv002,1,PR01,30,150
Inv002,2,PR03,10,800
,4,PR04,20,700
];
Here InvoiceID is 5th row is null, still showing Key and Information density 100% and Subset ration 100%.
i am bit confusion,
1.Perfect Key always Primary key,Unique Id and not null values Properly?
2.Subset ratio 100% means always having values Properly? .
if i understand wrong plz excuse.
Regards,
raja.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
in this case Qlikview is definitely wrong.
I suppose that you are using an old version of Qlikview (maybe 9?). I have heard that this bug of Qlikview has been fixed later.
I just put the code in QV 11 Personal, and it shows [Key] on both sides, as expected.
Also the density is wrong, and it appears wrong also in my version. This is probably because the spaces in the inline are seen as data.. But if you amend the code as follows, the density will change
Invoices:
LOAD
LEN(TRIM(InvoiceID)) AS LEN,
IF(LEN(TRIM(InvoiceID))=0,Null(),InvoiceID) AS InvoiceID,
ClientID
;
LOAD *
INLINE [
InvoiceID, ClientID
Inv001,CL0001
Inv002,CL0002
,CL0003
,CL0004
];
InvoiceDetails:
LOAD *
INLINE [
InvoiceID, InvoiceLine, ProductID, Quantity, Amount
Inv001,1,PR01,10,50
Inv001,2,PR02,10,40
Inv002,1,PR01,30,150
Inv002,2,PR03,10,800
,4,PR04,20,700
];
Here is how I see it:

It has density 50% (2 NULLs out of 4 records) and subset rati 67% (2 values out of 3, because the space is counted as a value).
If you change the code even more, you will have the most correct picture:
Invoices:
LOAD
LEN(TRIM(InvoiceID)) AS LEN,
IF(LEN(TRIM(InvoiceID))=0,Null(),InvoiceID) AS InvoiceID,
ClientID
;
LOAD *
INLINE [
InvoiceID, ClientID
Inv001,CL0001
Inv002,CL0002
,CL0003
,CL0004
];
InvoiceDetails:
LOAD
IF(LEN(TRIM(InvoiceID))=0,Null(),InvoiceID) AS InvoiceID,
InvoiceLine, ProductID, Quantity, Amount
;
LOAD *
INLINE [
InvoiceID, InvoiceLine, ProductID, Quantity, Amount
Inv001,1,PR01,10,50
Inv001,2,PR02,10,40
Inv002,1,PR01,30,150
Inv002,2,PR03,10,800
,4,PR04,20,700
];

Of course the data set is for test.. but for a correct data set you should never have a missing invoice ID!
I hope it helps
Francesco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From the Book QlikView 11 for Developers:
"The name of the field. Optionally, if the field is a key field, a qualifier is shown enclosed in square brackets. This qualifier indicates the following levels of key quality:
[Perfect Key] indicates that every row contains a key value, and that all of these key values are unique. At the same time, the field's subset ratio is 100 percent. This qualifier should be seen in dimension tables, where every key should uniquely identify a single record.
[Primary Key] indicates that all key values are unique, but not every row contains a key value or the field's subset ratio is less than 100 percent
[Key] indicates that the key is not unique. This qualifier is usually seen in fact tables, where the same dimension value may be associated with many different facts."
- « Previous Replies
-
- 1
- 2
- Next Replies »