Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: How to split a large QVD into year and Load in...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to split a large QVD into year and Load into Qlikview to handle large volume?
Hi all,
I have more than 100 million records in one of my fact tables and I am using the incremental load functionality, when I am creating qvd's <-- that is fine and it works. When creating a Datamodel, its taking more time due outer join between 3 big fact table. So,I would like to split the large QVD's and load into Qlikview. Have anyone come across same issues, please advice.
Thanks
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Loading can be done altogether using scripts like as below, but if you get all the data back in your application altogether, not sure how it is different than your current situation? If you can share script/data model, it will help.
For each vFileName in Filelist ('<Path>*.qvd')
Load *,
From [$(vFileName)];
Next vFileName
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Digvijay, is there a difference between your suggestion and
LOAD * FROM [*.qvd] (qvd);
?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have 2 table which has 100mil records till now and its growing daily.In current datamodel I am join these 2 table and creating a fact table, so loading time more and application is also slow. Due to this huge volume I would like to split the applications/QVD's, 1 with current set of data and history with respectively Qvd's \QVW's. Please advice me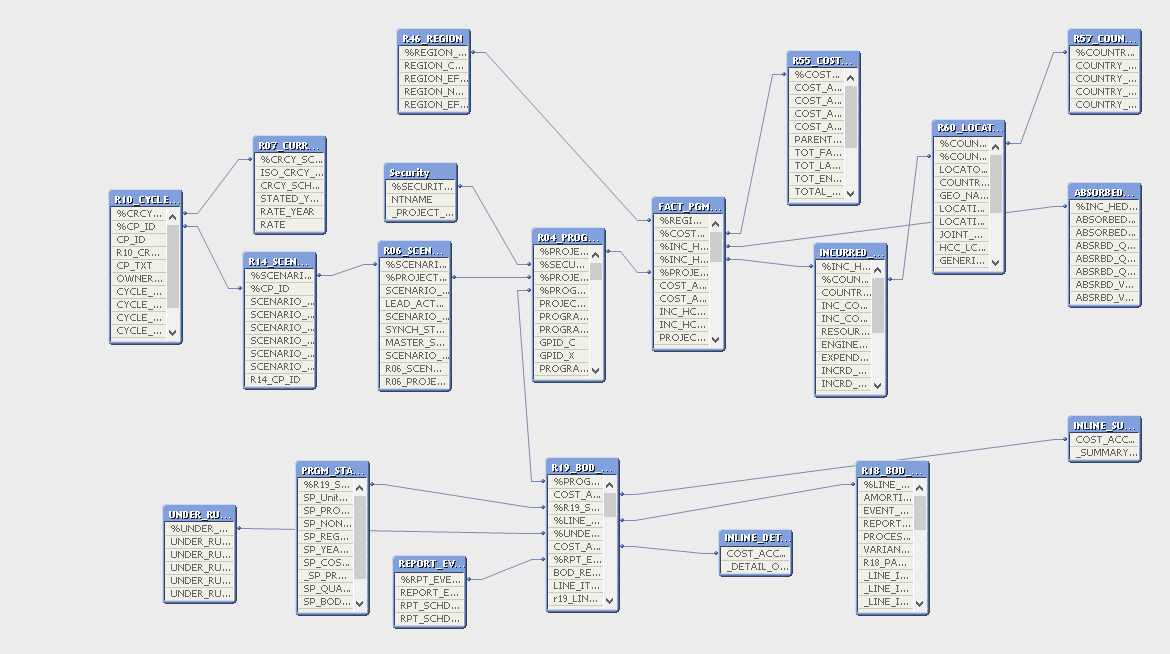
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
All of my thoughts on incremental load and splitting QVDs are in this blog post:
https://www.quickintelligence.co.uk/qlikview-incremental-load/
I hope that there is something that may help in there.
If you can segment your data into separate QVDs, perhaps by date or region, then you can load from just matching QVDs to get more limited data, e.g.
LOAD
*
FROM InvoiceHeader_201705.qvd (qvd);
LOAD
*
FROM InvoiceLine_201705.qvd (qvd);
This only works however if the grouped QVDs correspond.
If you need to get to the point where all the data is loaded in together, check the complexity of your keys between the tables. Make sure that you have no synthetic ones (these will kill a data model if you have many many rows). Keep with simple integer keys if you can.
You mention doing joins. If that is a JOIN (Table) LOAD in your load script then you probably want to avoid doing those anyway. Associations in the data model tend to perform better.
Hope that helps.
Steve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Both works but I think yours one is simpler, better.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- If there is any possibility you may think of implementing star schema to reduce no of hops( Currently you need to hop through 4-5 tables to associate information.)
- You can have current QVW with latest data and history QVW with old data, you can implementing document chaining to open history QVW in case required in some situations from the current QVW using triggers.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Some of the guidelines I've used when dealing with large (50 million+) data models. These are guidelines, not hard rules but they've helped out in the past.
1. Avoid synthetic keys (looks like you did - well done with all those table). We had one synthetic and the size of the QVW doubled and the response time was minutes - not seconds.
2. Associations with numeric fields. Autonumber is very handy for this but the drawback is having to create them all in the same script.
3. Limit fact table to numeric - measures and associations
4. Push for star schema over snowflake but if you have to snowflake, the further from the fact table, the fewer rows. I'll admit - I've broken this one a few times.
Our project was also well over 100 million and we cut the time with incremental loading on the backend to QVDs then a subsequent script would build the star schema. Load time went from hours to minutes and response time was down 90% in some cases.
Can some of the outer tables be joined? For example, locations and countries? I'm no expert but all those associations could be dragging performance. Interesting model. Also, check your key coverage in the tables.
HIC has a good article on table hops. A Myth about the Number of Hops
- « Previous Replies
-
- 1
- 2
- Next Replies »