Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Location and Language
- :
- Россия и СНГ
- :
- Re: Re: Расчет показателя с истории времен на ДАТУ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Расчет показателя с истории времен на ДАТУ (конец месяца, квартала, года)
Коллеги, добрый день.
Столкнулись с такой задачей:
Необходим расчет показателей НА ДАТУ – не за период «Дата С – Дата ПО», а на отчетную дату с «истории времен» : на конец месяца (на 31.01.2014), квартала (на 31.03.2014), года (на 31.12.2013), конкретную дату в календаре (на Сегодня).
В прилагаемом примере:
первый столбец – это ID убытка, следующие 2 столбца – это Дата заявления убытка (DATE1) и дата закрытия убытка (DATE2)
Ячейка E1 – конец отчетного периода, например: 01.06.2012 это значит считаем показатели на конец мая 2012 г.
В ячейке E2 формула MS Excel, которая дает нужный результат (как просили нас на встрече)
Со столбца G и далее – собственно табличка из Клика, в которой мы не можем сделать такую же формулу, как в Экселе, для расчета Newly registered, nb и Outstanding claims, nb
Заранее спасибо.
- Tags:
- Group_Discussions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Сергей, очень интересное решение, спасибо.
И насчет Set Analysis вы конечно правы - он помогает всегда. Как доброе слово.
А доброе слово и пистолет - помогает еще лучше. Как Set Analysis поверх специальным образом построенной модели данных  .
.
Я еще разбираюсь с вашим решением - общий смыл ясен но детали как обычно... В комментариях вы пишете, что эта модель принципиально готова дать детализацию по датам - но я пока не понимаю какие изменения нужно для этого внести в загрузочный скрипт.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
В этом комментарии я хочу показать почему именно мой вариант мне представляется предпочтительным.
На первый взгляд может показаться, что предложенная мною модель данных как то специально разработана для конкретно поставленной задачи.
На самом деле ничего специфического в этой модели нет. Думаю что ее можно было бы в стандартных терминах (Kimball) определить как (не буду искать корректных переводов) Dimensional model with Star Scheme and Transactional Fact table.
Попробуем разобрать это определение по частям:
Star schema: на этом примере звезда оказалась вырожденной, с одним лучом – я постараюсь в дальнейшем показать, что это не меняет сути дела.
Dimensional model: Это важный момент. Даже в этом простейшем виде, я думаю модель соответствует этому определению: Она состоит из Таблицы фактов и Таблиц измерений (в данном случае одной таблицы измерений). В таблице фактов каждому наблюдаемому событию соответствует ровно одна строка.
Transactional Fact Table: Ключевой момент, на мой взгляд. В основном таблицы фактов могут быть трех разновидностей Transactional, Periodic snapshot, Accumulating snapshot. В транзакционной таблице факта каждой строке соответствует конкретная операция в конкретный момент времени – продажа, покупка, приемка на складе, перемещение со склада на склад. В Periodic snapshot таблице каждой строке соответствует накопленное состояние наблюдаемого объекта на определенный момент времени. Например остаток номенклатуры по складу на конец дня, или конец месяца. (Количество незакрытых претензий на конец месяца тоже могло бы быть примером). В Accumulating snapshot строке факта соответствует операция, длящаяся во времени (workflow process) – например процесс заказа товаров поставщику. Строке соответствует заказ с датами создания заказа, регистрации заказа у поставщика, подтверждения, отгрузки от поставщика, приемки товара и т.д.
В нашем примере таблица исходных данных как раз напоминает таблицу Accumulating snapshot с мини-описанием процесса работы с претензиями со всего двумя этапами – регистрация новой претензии и закрытие ее.
Но выбор типа таблицы фактов должен зависеть не от структуры исходных данных – а от типов запросов, на которые должна будет отвечать модель.
Accumulating snapshot fact table: хорошо отвечает на вопросы о длительности тех или иных этапов в workflow процесса. Сложнее из него получать ответ – сколько тех или иных операций проходило за определенный период.
Periodic snapshot fact table: отвечает на вопрос о состоянии наблюдаемого объекта на определенный момент времени. Некоторая сложность работы с ним – меры в таких таблицах обычно не аддитивны по измерению времени. (Например остаток на конец года не равен сумме остатков на конец месяца по двенадцати месяцам того же года)
Transactional fact table: Идеально отвечает на вопросы об объеме тех или иных операций за заданный период времени. Меры обычно полностью аддитивны по всем измерениям.
На вопросы о длительности процессов не отвечает. На вопросы о состоянии на определенную дату – может отвечать при использованию календарей с возможностью аккумуляции (как в нашем примере).
Теперь возьмем нашу задачу: В требованиях есть два основных типа показателей (объемный показатель по количеству операций за определенный период «Newly registered» и показатель по накопленному состоянию на определенный момент времени «Outstanding claims». Исходя из этого можно сделать заключение, что Accumulating snapshot fact table на данный момент нам не нужен. Мы можем решить задачу либо комбинацией Transactional и Periodic snapshot fact tables либо использовать только Transactional тип факта со специализированным типом измерения времени.
Допустим мы выбрали тип Transactional fact table: В исходных данных в данном случае у нас таблица подобная accumulating snapshot, в каждой строке такой таблицы фактически зафиксировано два события – регистрация претензии, и затем закрытие этой претензии.
При загрузке данных мы делим эти события и таким образом у нас на каждую строку исходных данных получается минимум одна (если претензия незакрыта) максимум две строки таблицы данных. При этом вместо двух различных дат операции в исходных данных мы получаем единое измерение времени (Это очень важно, так как позволяет нам легко получать показатели по разным типам операций за один период времени. Accumulating snapshot не дает нам такой возможности). Кроме измерения времени в таблице фактов есть одно вырожденное измерение – тип операции. Measure (мера?) в таблице фактов одна. Она полностью аддитивна – по любому набору измерений (хотя их пока только два)
(Альтернативно мы могли бы не добавлять вырожденное измерение тип операции, а разнести единую меру на две – счетчик регистрации новых претензий и счетчик закрытия претензий)
Для обеспечения возможности получения данных по состоянию на определенную дату из Transactional fact table мы создаем расширенный календарь по методике описанной в http://community.qlik.com/docs/DOC-6593
Рассмотрим теперь, чего мы можем ожидать от подобной модели в плане масштабируемости, гибкости и расширяемости.
Масштабируемость: Таблица факта будет расти пропорционально таблице исходных данных (количество строк в таблице факта строго менее количества строк в исходной таблице x 2). Таблица измерения календарь будет расти значительно в зависимости от периода наблюдения (за год количество строк будет 18 тыс., за два полных года 268 тыс., за три полных года 600 тысяч)
Гибкость – меры в таблице фактов строго аддитивны (в том числе за счет от отказа от использования Periodic snapshot fact), так что мы не ожидаем сложностей с выводом показателей в разрезах различных измерений.
Расширяемость – мы не ожидаем сложностей с моделью при добавлении новых измерений либо новых мер.
Для того чтобы протестировать эти ожидания на соответствие действительности добавим несколько требований к первоначальному заданию:
- Отобразить количество закрытых претензий за определенный период
- Отобразить количество закрытых претензий накопительно с начала времен
- Добавить меру «Сумма по претензии»
- Отобразить Суммы по новым зарегистрированным, закрытым и незакрытым на конец периода претензиям
- В качестве измерения времени в таблице отчета позволить выбирать квартал, месяц, неделю, день
- Добавить измерения «Тип претензии», «Контрагент», «Отдел». Все предыдущие показатели в таблице отчета должны отражаться корректно с учетом фильтров наложенных в этих измерениях.
- Все предыдущие показатели должны отражаться корректно с учетом фильтров наложенных на измерения «Квартал», «Неделя», «Месяц», «Дата»
Эти требования реализованы во вложенном приложении, для загрузки необходим обновленный файл исходных данных с добавленными данными по новым измерениям и по сумме претензий.
![QlikView x64 - [C__Projects_OutstantingClaims_OutstandingClaims_v2.qvw] 2014-07-20 17.06.03.png](/legacyfs/online/62737_QlikView x64 - [C__Projects_OutstantingClaims_OutstandingClaims_v2.qvw] 2014-07-20 17.06.03.png)
Видно, что в результате этих изменений модель визуально стала больше похожа на звезду.
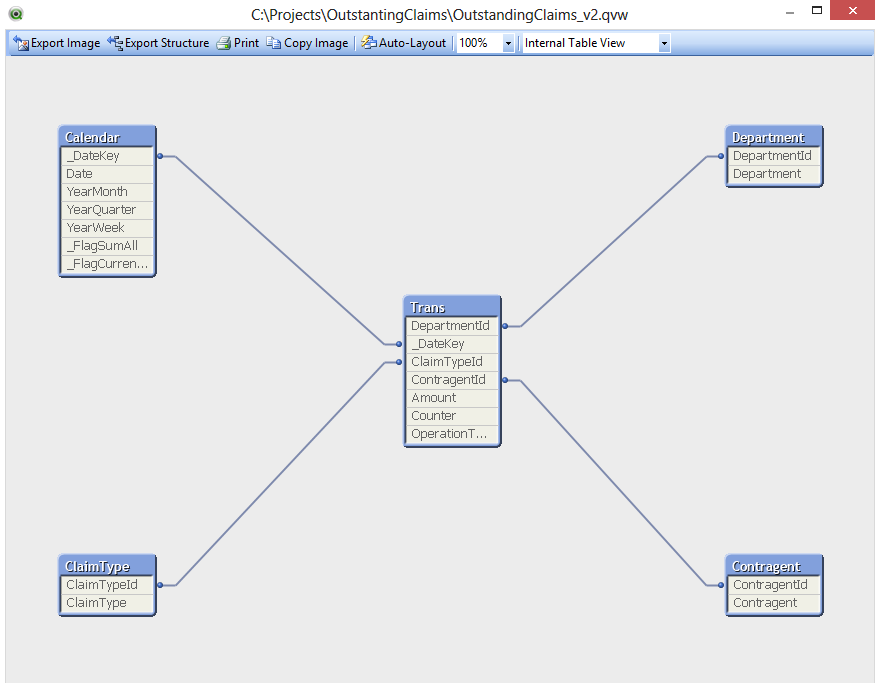
Некоторые замечания по реализации:
- Для добавления показателей по закрытым претензиям в модель не пришлось вносить никаких измерений. Достаточно было добавить два выражения аналогичным выражениям по вновь зарегистрированным претензиям
- Для добавления суммы по претензиям – достаточно было добавить значения в исходные данные, загрузить в модель, добавить выражения (полностью аналогичные выражениям по количеству претензий)
- Для добавления новых измерений – достаточно было добавить их в исходные данные и загрузить в модель
- «Квартал», «Неделя» - достаточно было добавить эти измерения в календарь при загрузке, добавить циклическую группу Календарь и использовать ее в таблице отчета. За счет того, что все показатели модели полностью аддитивны нет необходимость что-либо адаптировать под то либо другое измерение. Фильтры по измерению времени работают корректно, так как все показатели аккумулирующие данные с начала времен работают на уровне модели. (Вместо того, чтобы использовать переключатель Full accumulation на обычном выражении)
Вывод, который мне видится: Даже если задача видится специфической и индивидуальной – зачастую целесообразно для нее подобрать решение из стандартного набора. Даже если это покажется немного «навырост» для задачи в ее первоначальном виде.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Я не вижу противоречий в используемых нами подходах, так или иначе основанных на использовании календаря, включающего в себя все варианты пересечений используемых дат. Создавая пример приложения, я ставил перед собой лишь две задачи:
- Ответить на вопрос, показавшийся мне наиболее существенным: "Можно ли решить эту конкретную задачу использованием Set Analysis и если нельзя, то почему?".
- Продемонстрировать подходы к решению задачи так, чтобы у читателя возникло понимание конкретной последовательности действий, приводящих к искомому результату.
- В части оптимизации моделей я обычно предпочитаю не доказывать идеальность конкретной модели, а рассказываю лишь о нескольких собственных практических уроках, вытекающих из логики работы ассоциативной модели QlikView:
- В реляционной модели данных, все правила оптимизации в первую очередь направлены на минимизацию объема хранимых данных. Выбор же итоговой ассоциативной модели QlikView в общем случае определяется логикой разработчика направленной на достижение удобства последующего представления и отбора данных конечными пользователями при решении ими конкретных задач. Это важно, т.к. в отличие от реляционной модели, с моделью QlikView может работать конечный бизнес-пользователь, т.к. работает с ней не как с набором таблиц, представленных в виде схем "снежинка", "звезда" и прочих, а как с общим множеством взаимосвязанных данных (не задумываясь о принципах построения взаимосвязей). Т.е. вопросы схемы модели в большинстве случаев, это - вопросы разработчика, а не пользователя. И зачастую запросы пользователя, как конечного потребителя модели - заставляют отказываться от "стройности" модели придуманной разработчиком на первых этапах.
- В части оптимизации производительности и объема используемой оперативной памяти почти всегда действует правило: отбор в одной таблице происходит быстрее, чем по любой цепочке. При этом далеко не всегда формирование общей таблицы требует большего объема оперативной памяти за счет того, что QlikView хранит только уникальные наборы данных. В результате подход направленный на минимизацию количества таблиц становится существенным на больших объемах данных.
- С точки зрения корректности использования и отладки выражений Set Analysis, всегда проще работать с меньшим количеством таблиц. В частности, нужно быть предельно аккуратным в случае использования set-операторов в сочетании с расчетами функций агрегации на основе полей, размещенных в различных таблицах.
- Как уже упоминал выше, в процессе работы пользователей их задачи имеют тенденцию меняться и зачастую изменение задач приводит к изменению существующих моделей или появлению дополнительных.
- Еще раз подчеркну, что предложенный мной вариант является примером для "понимания сути" выполняемых действий по подготовке модели данных, обеспечивающей решение поставленной задачи. Выбор же конечной модели предлагаю сделать тем, кто будет решать конкретную задачу с пониманием всех "хотелок" пользователя. Моя практика такова, что не существует "идеальных" моделей на все случаи жизни. Особенно это справедливо для действительно больших наборов данных, где основной задачей становится не столько "красота" и понятность модели в плане соответствия ее исходным данным, сколько сохранение быстрого отклика приложения на любое действие пользователя.
По просьбе Вадима прикладываю вариант ранее предложенного приложения с отображением данных по датам, месяцам и кварталам.
Выбор модели - за исполнителем .
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Сергей, спасибо за обновление.
Интересный диалог получился
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Да, спасибо за это всем участникам!
Хотелось бы еще услышать точку зрения автора этой дискуссии:
1. Получил ли он ответ на свой вопрос?
2. Достаточно ли ему предоставленной информации?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Коллеги, добрый день.
Спасибо за предоставленные комментарии.
Налицо необходимость изменения нашей существующей модели (изменение загрузочного скрипта, обогащение модели новыми разрезами).
Это в компетенции специалистов нашего ИТ департамента.
По итогам обсуждения с ними обязательно отпишусь.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Здравствуйте.
Я прошу прощения, что не сути дела.
Мне Очень понравилось и сдержаться и не выразить Благодарность не могу.
СПАСИБО
Михаилу Александровичу за тему и пример.
Вадиму за классификацию таблиц фактов и подробное объяснение Логики движения к результату.
Сергею за нацеленность на Результат, иногда вопреки поиску дальнейшей красоты кода и веру в SET ANALYSIS.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Добрый день!
Прилагаю вариант решения вашей задачи без "второго" календаря.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Коллеги, добрый день.
Был на QRUGе 5 декабря, похожую тему освещал Андрей Терехов - мой вопрос относится к категории сальдовых показателей в динамике (а не просто расчета показателей на дату - сальдовые показатели без динамики).
Насколько я понял автора, мой вопрос решается в основном предрасчетом нужных показателей на этапе загрузки - что мы и сделали.
Спасибо.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Антон, спасибо за ответ, изучим ваш вариант.