Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics & AI
- :
- Products & Topics
- :
- App Development
- :
- Left Join + IntervalMatch causing count() to be in...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Left Join + IntervalMatch causing count() to be incorrect?
Hello all,
I'm attempting to associate a timestamp in one table with the shift date in another at the bottom of the code posted below.
If I remove the underlined portion of the script(the portion that associates the two tables), I will get the correct count() when setting up my dimension on a bar graph but of course then the shift is no longer connected to the timestamp. The numbers are not even close it goes from a total of 10k for one error message to 7.2 million.
Any insight into why this is happening, suggestions for alternative ways to do this, or critiques of other portions of the script would all be helpful.
[log]:
LOAD
SubField(Object,',',1) as Machine,
SubField(Object,',',2) as Order,
SubField(Key,',',1) as Product,
SubField(Key,' ',2) as Code,
SubField(Key,'-',2) as [Error Message],
Text,
"Timestamp",
"UserID",
NewValue As Comments;
SQL SELECT
Object,
Key,
Text,
"Timestamp",
"UserID",
NewValue
FROM Plant.dbo.Log
WHERE Text LIKE 'O%';
[Shifts]:
Load
ShiftPlannedStart,
ShiftPlannedEnd,
Replace(Replace(Replace(Replace(Replace([ShiftName],'A','1'),'B','2'),'C','3'),'D','4'),'E','5') as [Shift];
SQL Select
ShiftPlannedStart,
ShiftPlannedEnd,
ShiftName
FROM Plant.dbo.Info;
Temp:
Left Join (log)
IntervalMatch("Timestamp")
Load ShiftPlannedStart, ShiftPlannedEnd
Resident Shifts;
Left Join (log)
Load *
Resident Shifts;
Drop Table Shifts;
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well, I haven't understood your last sample and where the log.ShiftPlannedStart is located vs ShiftPlannedStart.
As far as I see, the duplicates in your shift table will cause the incorrect count after Joining the tables (as long as you keep them unjoined, a count in the log table will be correct, no duplication of records due to the JOIN).
--> Check your shifts table, consider using a DISTINCT LOAD of shifts.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
why rush to the removal of the intervalmatch() resulting table?
i know it's a synth key... but start by assessing the matching worked.
just try
IntervalMatch("Timestamp")
Load ShiftPlannedStart, ShiftPlannedEnd
Resident Shifts;
without any additionnal join.
(and if the results are wrong, begin checking formats and interpretation of timestamps)
(also are your shifts mutually exclusive / no overlapping? )
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In addition, what is the dimension and the field you are counting (with or without DISTINCT?)?
Have you checked that the Timestamp is actually linked to incorrect shift time spans?
If your shift table contains a lot of duplicates (for example, records per worker, but worker is not loaded), this also might explain an increased count().
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the input Mikael,
I've modified the last portion of the script to be...
[Shifts]:
Load
ShiftPlannedStart,
ShiftPlannedEnd,
Replace(Replace(Replace(Replace(Replace([ShiftName],'A','1'),'B','2'),'C','3'),'D','4'),'E','5') as [Shift];
SQL Select
ShiftPlannedStart,
ShiftPlannedEnd,
ShiftName
FROM Plant.dbo.info;
Temp:
IntervalMatch("Timestamp")
Load ShiftPlannedStart, ShiftPlannedEnd
Resident Shifts;
Hopefully this is what you where suggesting to try. As you mentioned it did create a synthetic key, which from what I understand people usually try to avoid because of performance/memory issues?
The data manager and "load" function both completed in a short period of time so I don't have any concerns there.
The modified script above accomplished exactly what I wanted, I have all the associations I need as well as the correct count. Thanks for the help.
Do you have any idea why the original script was causing an issue using the count() function?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try
Temp:
inner Join (log)
IntervalMatch("Timestamp")
Load ShiftPlannedStart, ShiftPlannedEnd
Resident Shifts;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In addition, what is the dimension and the field you are counting (with or without DISTINCT?)?
Originally I was counting "text" but have tried other dimensions such as "code", and "machine".
"Text" is a column filled with the same data in every row. My purpose of using Count() was to get the total of every occurrence but I did try Count(Distinct just to see the behavior and as expected it only count 1 instance per day.
Have you checked that the Timestamp is actually linked to incorrect shift time spans?
The timestamp is linked to the correct shift spans.
If your shift table contains a lot of duplicates (for example, records per worker, but worker is not loaded), this also might explain an increased count().
Currently I'm loading ShiftplannedEnd, ShiftPlannedStart, and Shift.
ShiftPlannedEnd or ShiftPlannedStart should not have any duplicates as it is the a combination of a date with a specific time
ShiftPlannedStart
1/1/2014 2:30PM
1/1/2014 10:30PM
1/2/2014 6:30AM
1/2/2014 2:30PM
ShiftPlannedEnd
1/1/2014 2:29:59PM
1/1/2014 10:29:59PM
1/2/2014 6:29:59AM
1/2/2014 2:29:59PM
Shift does contain a significant amount of duplicates as, depending on the ShiftPlannedStart it will be either a 1-5 for every entry.
Your saying this could be the reason for the count() increase?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
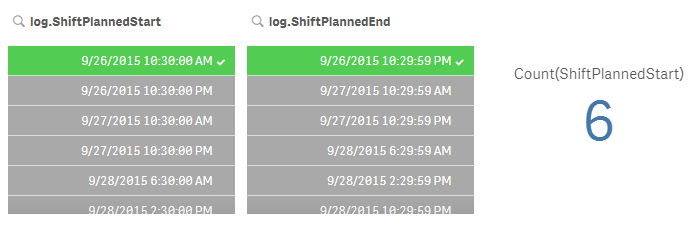
If you select a specific shift (Shift start and end timestamp), what does a
Count(ShiftPlannedStart)
return?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So it definitely seems there are duplicates but I'm still unclear how and how this creates duplicates of other dimensions such as "text".
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Wouldn't we expect a unique record per shift?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes I'm not sure where the duplication is coming from. With only the ShiftPlannedEnd highlighted here I would expect to see 8.11K instances of "9/27/2015 10:30:00 PM" but we only see one.

- « Previous Replies
-
- 1
- 2
- Next Replies »