Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics & AI
- :
- Products & Topics
- :
- App Development
- :
- Re: Strange Join considering Occurrence
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Strange Join considering Occurrence
Today i have to face a little bit strange situation...
Have these two tables:
Tab1:
| Qty (Key) |
|---|
| 20 |
| 20 |
| 10 |
| 30 |
| 10 |
| 30 |
Tab2:
| Delivery | Qty (Key) |
|---|---|
| 1 | 30 |
| 2 | 10 |
| 3 | 10 |
| 4 | 20 |
| 5 | 30 |
| 6 | 20 |
Qty field is the key field between these tables.
I want to associate the first occurence of Tab2.Qty with the first occurence of Tab1.Qty, the second occurrence of Tab2.Qty with the second occurrence of Tab1.Qty... and so on, respecting the original sort order fo Tab2.
So the association would be:
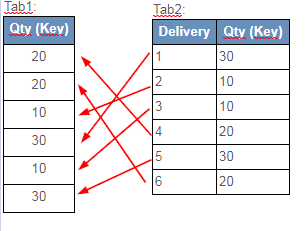
In order to obtain this result:
FinalTable:
| Qty | Delivery |
|---|---|
| 20 | 4 |
| 20 | 6 |
| 10 | 2 |
| 30 | 1 |
| 10 | 3 |
| 30 | 5 |
How to do this ?
If a post helps to resolve your issue, please accept it as a Solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Key column should not have duplicates. Try to identify any column, which help you to identify each row uniquely.
else try to generate your own unique key to perform join.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm sorry, but isn't your FinalTable exactly the same as your Tab2 ?
If you need a more precise association because of other fields available, then you'd need to finetune your Key. e.g. concatenate with another variable that distinguishes between 2/10 and 3/10. Could be delivery address, delivery name, date&hour, ....