Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Location and Language
- :
- Brasil
- :
- Leitura dos arquivos "QVD"
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Leitura dos arquivos "QVD"
Pessoal, bom dia!
Trabalho em um projeto que tive a necessidade de implementar o conceito de "QVD's", ou seja, um arquivo responsável por realizar a carga das fontes de dados e transformá-los em arquivos do tipo "QVDs" (GERA_QVD). Do outro lado possuo outro arquivo responsável por fazer a leitura dos arquivos "QVD's" (PAINEL_CLIENTE).
No arquivo (GERA_QVD) é gerado um arquivo QVD diário para cada tabela fato e somente um para cada dimensão. Este processo leva em média 7 minutos para ser realizado, pois apesar da carga ser realizada somente no dia as consultas são pesadas.
No arquivo (PAINEL_CLIENTE) é feita a leitura dos arquivos "QVD's" (Todos os dias). Este processo leva muito tempo, em torno de 40 minutos e para piorar o cenário, caso algum usuário esteja utilizando o publicador no momento da carga este tempo aumenta para mais de uma hora.
Observei que por definição padrão o arquivo (PAINEL_CLIENTE) joga fora tudo que está armazenado para ler novamente todos os "QVD's". Gostaria de saber se existe alguma maneira de incrementar somente o dia ...
Att,
Brander Weten.
- Tags:
- Group_Discussions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Brander,
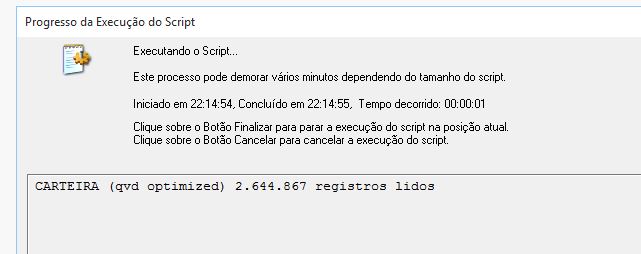
Tem que verificar se no seu Painel, os QVDs estão sendo lidos de modo otimizado (Na imagem esta apos o nome).
O QVD é a representação de uma tabela como esta "in memory" no Qlik . Então, ler ele sem nenhum where (exceto o Exists() ) ou algum tipo de transformação (ex: year(Data) ) faz com que leia algo como 1 milhão de registros por segundo em media. Da para ver na imagem que foi lido quase 3 milhões em 1 segundo.
Agora, se não estiver sendo lido otimizado (se tiver qualquer coisa dita antes por exemplo entre outras possíveis ) a leitura ficara bem mais lenta.
nicolett.yuri tem um excelente post sobre isto
Sobre o incremental, daria para ler o dia e juntar com os dias anteriores.....exemplo:
//=======================================================================================================
// VBUK
//
LET v_Tem_VBUK = if(QvdNoOfRecords('$(vStagePath)VBUK.QVD')>0,1,0);
//
//
[VBUK]:
SQL Select VBELN GBSTK from VBUK Where VBELN in (Select VBELN from VBAK Where ERDAT >= '$(Data)' or AEDAT >= '$(Data)');
//
if $(v_Tem_VBUK) = 1 then
TRACE ** Unindo os dados do QVD com a tabela VBUK **;
Concatenate (VBUK)
LOAD * FROM [$(vStagePath)VBUK.QVD] (qvd) Where not Exists(VBELN);
ENDIF
STORE VBUK Into $(vStagePath)VBUK.QVD (qvd);
DROP Table VBUK;
//
//=======================================================================================================
Neste exemplo, se existe um arquivo .QVD a leitura do dia sera juntada com a do QVD e assim, fica um arquivo .QVD com todas as informacoes (tem um not exist() para nao ler do QVD dado ja existente...).
Depois, no painel poderia ser lido um arquivo ao invés de dezenas ou centenas......
Ainda tem a leitura parcial,
add load
add only load
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
A leitura do script é realizada de forma otimizada, mas como eu gero um arquivo por dia ao invés de incluir os dados dentro do único QVD este processo é bem demorado. Eu vou pegar o exemplo que você citou e fazer um teste, provavelmente este é o caminho.
Att,
Brander Weten.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Cuida se fizer carga debug de alguns registros, você perde o .QVD com todos os dados. O que já fiz (não esta no código passado) seria ver a qtde de registros lidos em RAM, a qtde de registros no QVD e se for maior, gravar o QVD.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Já conseguiu solucionar? Se sim, marque uma das respostas como "Correta" e nos ajude a manter os foruns organizados.