Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Blogs
- :
- Technical
- :
- Design
- :
- Autonumber function
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Today I decided to blog about the Autonumber function that can be used to create a “compact memory representation of a complex key.” Having recently learned about this function, I realized there have been times in the past when this would have been helpful to use. For instance, when I need to build a link table in my data model, I often create keys that I use to link the tables. Sometime these key fields are lengthy and are a combination of 3 or 4 fields. In this blog, I will show you how you can use the Autonumber function to create a “compact memory representation of a complex key.”
Assume I load a data set that looks like this:
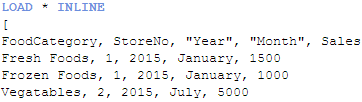
And I want to load another data set that looks like this:
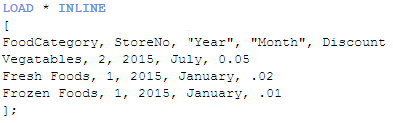
These two data sets have the same first four fields so if I were to load them as is, I would get a synthetic table in my data model. To avoid that I will set up a key field in each of the tables that includes the FoodCategory, StoreNo, Year and Month fields. This key field will be the field that links these two tables. I will do this using a preceding load when I load both of these tables. The script would look like this:
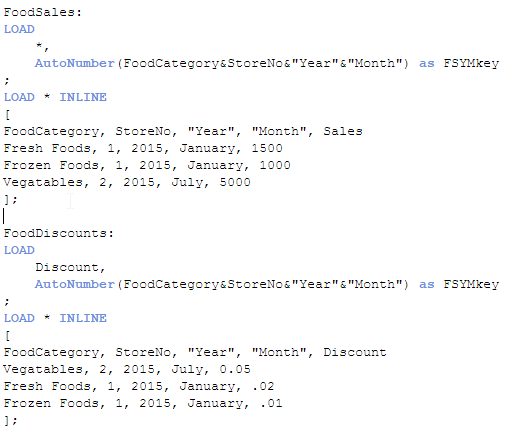
In the first table, I am using a preceding load to load all fields and then I am using the Autonumber function to create a key field that represents the four fields: FoodCategory, StoreNo, Year and Month. I am doing the same thing in the second table I am loading but the difference here is that I am not loading the key fields. By not loading the key fields, I am preventing a synthetic table from being loaded. The end result looks like this:

Notice the FSYMkey field. In this example, it is a unique integer that represents a larger expression. In the past, I would have created the key field like this (see the FSYMkey2 field in the table below):

FSYMkey2 is a more complex field that would have taken up more memory. This example is small but if you had thousands of unique key fields like this, the consumed memory would add up. By using the Autonumber function, I was able to use an integer to represent a long string thus minimizing the memory usage in my app. This is one of many tricks that can be used to reduce the memory usage in your app. Henric Cronstrom has some other ideas in his Symbol Tables and Bit-Stuffed Pointers blog. Check it out.
Thanks,
Jennell
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.