Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Location and Language
- :
- Francophones
- :
- Re: Probleme de jointure
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Probleme de jointure
Bonjour,
j'ai 2 fichiers:
Facture de janvier:
| Nom | Numéro | Organisation | periode | Montant Net | Nom de la rubrique | Nom de la sous-rubrique | Nom de la rubrique de niveau 1 |
Catégorie:
| Catégorie | Sous catégorie | Nom de la rubrique | Nom de la sous-rubrique | Nom de la rubrique de niveau 1 |
je veux avoir un tableau qui regroupe les 2 suivant les champs en commun: nom de la rubrique, nom de la sous-rubrique,Nom de la rubrique de niveau 1 et faire le filtre avec les nouvelles catégories et sous catégories mais mon probleme ce pose avec le champ de la sous rubrique et ses valeurs: com(13/01 au 17/01) car dans le fichier catégories dans la sous rubrique j'ai que com.
comment pourrai je faire ça?
Merci
- Tags:
- Group_Discussions
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ajoutez le paramétre 1 dans le substring, pour le forcer sur la premiére partie (qu'il prend par défaut chez moi) :
= RTrim(subfield([Nom de la sous-rubrique], '(', 1))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bonjour,
Enfaite si vous n'avez que ces deux tables la, le plus simple et de faire une vrai jointure avec un left join dans un premier temps. Ca vous permettra de faire disparaître la table synthétique qui n'est pas recommandée.
Ensuite, pour le com si vous voulez seulement récupérer les 3 premiers caractéres vous pouvez utiliser left(...,3).
Facture:
LOAD Nom,
Numéro,
periode,
month(periode) as mois,
Year(periode) as année,
[Montant Net],
[Nom de la rubrique],
left([Nom de la sous-rubrique], 3) as [Nom de la sous-rubrique],
[Nom de la rubrique de niveau 1],
replace(
replace(
replace([Organisation],'Celio','Cel'),
'Celi','Cel'),
'Clami','Clam') as Organisation
FROM
(biff, embedded labels, table is [janvier 2017$]);
left join
LOAD Catégorie,
[Sous catégorie],
[Nom de la rubrique],
[Nom de la sous-rubrique],
[Nom de la rubrique de niveau 1]
FROM
(biff, embedded labels, table is Feuil1$);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bonjour, Merci pour votre réponse .
Le probleme est dans le com car j'ai d'autre valeur plus longue que 3 donc je pense utiliser replace:
replace([Nom de la sous-rubrique],'com*','com')
pour chercher les valeurs qui contiennent com mais je sais pas si la syntaxe est correct?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Car aussi pour le champs sous rubrique la valuer ou il y a com(13/01 au 17/01) sa change d'un mois aun autre (13/02 au 17/02) (13/03 au 17/03)..... donc je ferai une recherche que sur la partie commune qui est com
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ah oui en effet je n'avais pas fait attention désolé.
Vous pouvez essayé : RTrim(subfield([Nom de la sous-rubrique], '('))
On récupére tout ceux qu'y a avant la parenthése et on supprime les espaces de fin.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
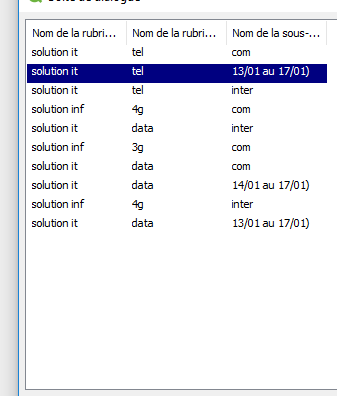
il me donne la chaine de fin et pas de début
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ajoutez le paramétre 1 dans le substring, pour le forcer sur la premiére partie (qu'il prend par défaut chez moi) :
= RTrim(subfield([Nom de la sous-rubrique], '(', 1))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ça marche très bien merci bcp .
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
je voudrais juste vous demander dans le cas ou il y a pas les () pour délimiter , comme dans ce cas la sous rubrique est: Appels Depuis Monde Evol Palier 0-30 Min et je veux recuperer que Appels Depuis Monde Evol je fais le délimiteur comme = RTrim(subfield([nom de la sous-rubrique], 'Palier', 1))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Oui tout à fait, sachant que si le champs [nom de la sous-rubrique] est une liste de valeur prédéfinis on peut passer par du mapping plutôt que d'avoir un subfield pour chaque cas, a tester.
- « Previous Replies
-
- 1
- 2
- Next Replies »