Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Concatenate to table only rows that does not exis...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Concatenate to table only rows that does not exist based on key column
Hi all
In a script for Inventory calculation ,
I wish to add rows from a table only in cases when they do not exist in the first table based on an id.
Here is the script:
I saw an old post - https://community.qlik.com/t5/QlikView-App-Dev/Concatenate-Load-Where-New-ID-Not-Exists/td-p/785812
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I was actually just looking at this yesterday. I don’t really get it myself yet, but below is an article I found. It seems like you need to rename the original key column to a temporary name and use that as your first iD in the where not exist clause.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
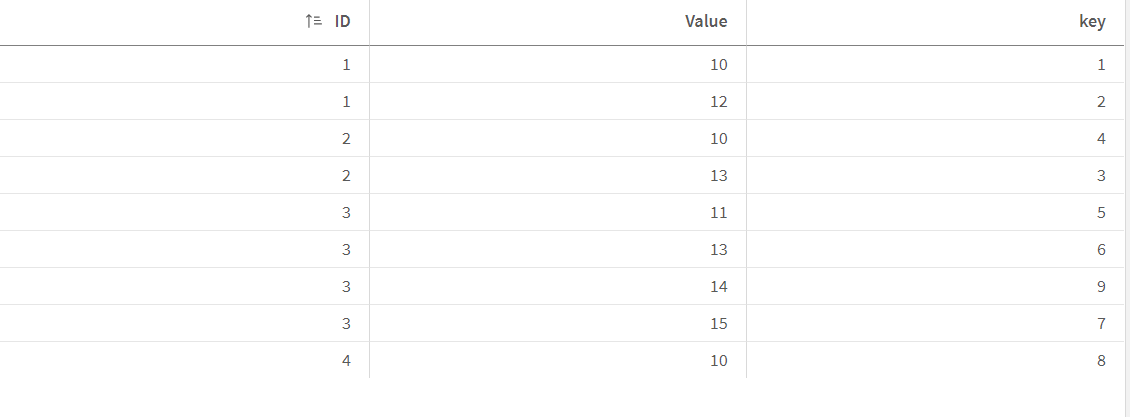
try something like this , create a composite key and apply distinct to remove duplicates
tab:
load ID,Value;
load * inline
[ID,Value
1,10
1,12
2,13
2,10
3,11
3,13
3,15
];
concatenate
load ID,Value;
load * Inline
[
ID,Value
2,13
2,10
2,13
2,10
4,10
3,14
];
NoConcatenate
tab1:
load Distinct ID,Value,key;
load ID,Value,
Autonumber(ID&Value) as key
resident tab;
drop table tab;
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think your approach should be working without doubling the field or renaming them or using exists() with a second parameter. If not it hints more for issues with the data-quality respectively the data are different to your expectation.
To detect it you could add an extra SOURCE field to each load with values like 'Inv' and 'Open' and also a rowno() as RowNo. Then use a table-box within the UI with these fields and your key to see how many identically key-values are there and from which source they are coming.