Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Count occurrences
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Count occurrences
Hi All,
I am trying to count the number of instances for each field.
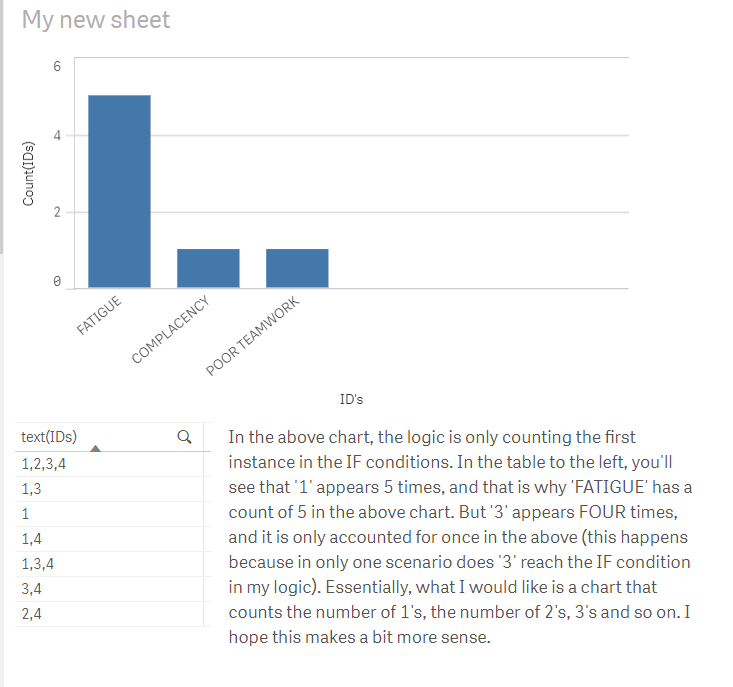
Please note: This is the script that I am using, and it is a master dimension. I can change the logic within the master dimension, but I cannot change the measures that I am using in the actual app. (I know that this is easily possible if I simply have a separate measure for each of the IDs)
=if(WildMatch(IDs,'1,*')=1 or IDs = '1', 'FATIGUE',
if(WildMatch(IDs,'*,2,*')=1 OR WildMatch(IDs,'*,2*')=1 OR IDs ='2', 'DISTRACTION',
if(WildMatch(IDs,'*3,*')=1 or IDs = '3' or WildMatch(IDs,'*,3,*')=1, 'COMPLACENCY',
if(WildMatch(IDs,'*4*')=1 , 'POOR TEAMWORK'
))))
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try this
Pick(Match(ValueList('FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK'), 'FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK'),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'Q'}>}IDs), 1), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'Q'}>}IDs), 2), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'Q'}>}IDs), 3), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'Q'}>}IDs), 4), IDs)))
Pick(Match(ValueList('FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK'), 'FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK'),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'W'}>}IDs), 1), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'W'}>}IDs), 2), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'W'}>}IDs), 3), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'W'}>}IDs), 4), IDs)))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
stalwar1, sorry I wasn't able to attach a document and image in our message, so this was the option I had to proceed with. Any help is greatly appreciated.
Mohamed
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
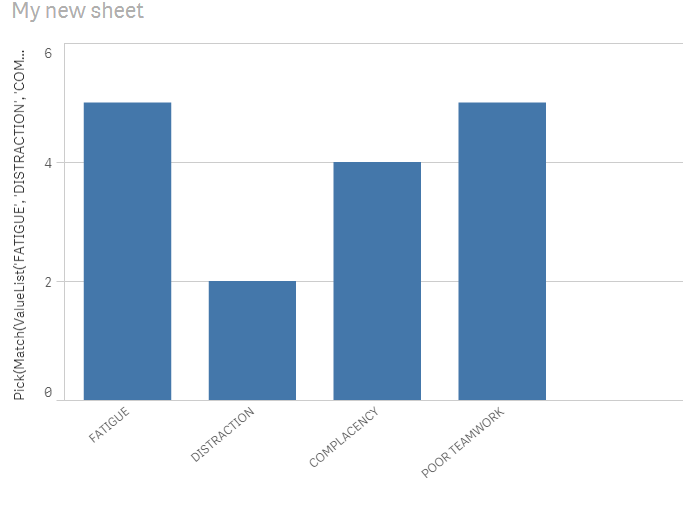
Try this
Dimension
=ValueList('FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK')
Expression
Pick(Match(ValueList('FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK'), 'FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK'),
Sum(Aggr(NODISTINCT SubStringCount(IDs, 1), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(IDs, 2), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(IDs, 3), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(IDs, 4), IDs)))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
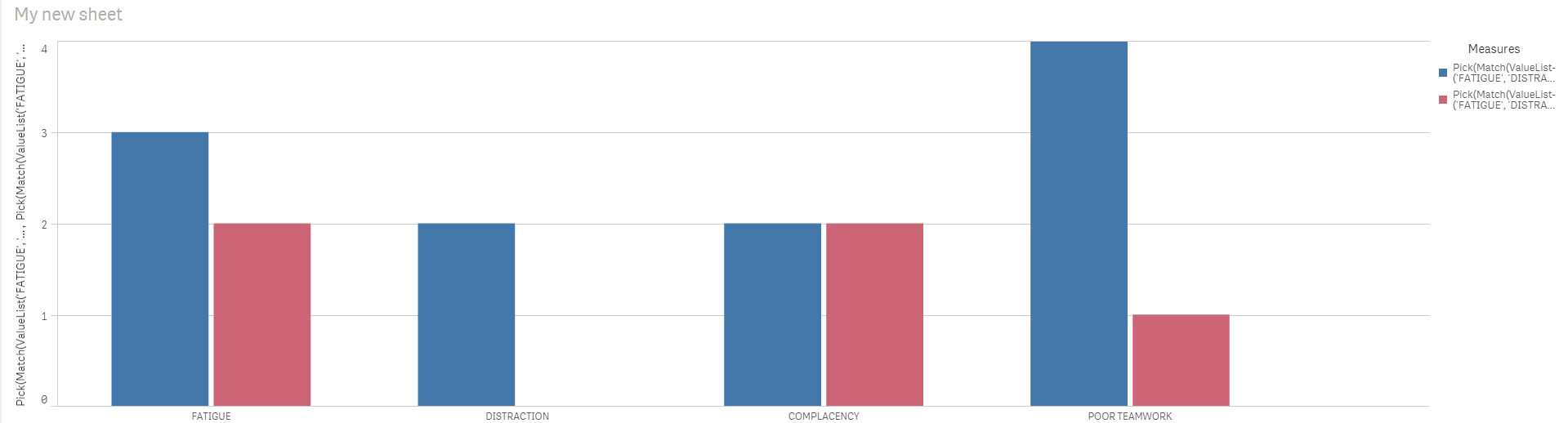
Hmm, I guess I should have been more thorough with my example. Please see the attached qvf. There are two distinct groups that I am counting for. When implementing for one group, yours worked well on the larger data set that I have, but when implemented for two groups, I get no visualization, unfortunately.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try this
Pick(Match(ValueList('FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK'), 'FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK'),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'Q'}>}IDs), 1), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'Q'}>}IDs), 2), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'Q'}>}IDs), 3), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'Q'}>}IDs), 4), IDs)))
Pick(Match(ValueList('FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK'), 'FATIGUE', 'DISTRACTION', 'COMPLACENCY', 'POOR TEAMWORK'),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'W'}>}IDs), 1), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'W'}>}IDs), 2), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'W'}>}IDs), 3), IDs)),
Sum(Aggr(NODISTINCT SubStringCount(Only({<Workmanship = {'W'}>}IDs), 4), IDs)))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This didn't quite give me the correct response, as it didn't scale to the number of ID's that I have in the actual app (17), so I made some tweaks and it seemed to work properly. I used a sum(wildmatch(),1), but still used the pick(match(valuelist())). Thank you very much.