Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Re: How can I compute only the first occurrence of...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How can I compute only the first occurrence of field value?
Hello QV community,
I'd be grateful if someone could help me with the following issue.
I have the following source file
| ID_1 | ID_2 | VALUE_1 | VALUE_2 |
| AAA | 111 | 500 | 500 |
| AAA | 222 | 500 | 500 |
| BBB | 333 | 600 | 600 |
| BBB | 444 | 600 | 600 |
I need to compute only the first occurrence of ID_1 during LOAD
So, I need to perform the operation only the first time ID_1=AAA.
Same thing for ID_1=BBB
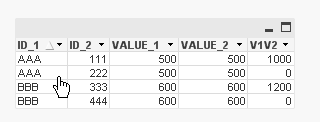
| ID_1 | ID_2 | VALUE_1 | VALUE_2 | [VALUE_1+VALUE_2] |
| AAA | 111 | 500 | 500 | 1000 |
| AAA | 222 | 500 | 500 | 0 |
| BBB | 333 | 600 | 600 | 1200 |
| BBB | 444 | 600 | 600 | 0 |
LOAD DISTINCT ID_1 does not work in this situation, Is there any other way I can solve this?
Regards,
Leonardo
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
a:
LOAD ID_1, ID_2, VALUE_1, VALUE_2
FROM [http://community.qlik.com/thread/138508] (html, codepage is 1252, embedded labels, table is @1);
a2:
NoConcatenate
LOAD ID_1, ID_2, VALUE_1, VALUE_2,
if(Peek(ID_1) <> ID_1, VALUE_1 + VALUE_2, 0) as V1V2
Resident a
Order by ID_1, ID_2;
DROP Table a;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi.
If you want to calculate the sum in the script use if() and previous() functions to check if the ID_1 value of the previous row is the same as the current row.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Whiteline,
I really appreciate your prompt reply.
I'm afraid that I didn't publish the best example. Sorry, my fault.
The actual question would be "How I can compute only one occurence of field value?"
AAA values are not necessarily together, as depicted in example below.
One thing to consider: Even though ID_2 may change, the combination ID_1, VALUE_1 and VALUE_2 is always the same.
That is, whenever ID_1 is AAA, VALUE_1=500 and VALUE_2=500
| ID_1 | ID_2 | VALUE_1 | VALUE_2 |
| AAA | 111 | 500 | 500 |
| AAA | 222 | 500 | 500 |
| BBB | 333 | 600 | 600 |
| BBB | 444 | 600 | 600 |
| AAA | 555 | 500 | 500 |
| BBB | 666 | 600 | 600 |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
a:
LOAD ID_1, ID_2, VALUE_1, VALUE_2
FROM [http://community.qlik.com/thread/138508] (html, codepage is 1252, embedded labels, table is @1);
a2:
NoConcatenate
LOAD ID_1, ID_2, VALUE_1, VALUE_2,
if(Peek(ID_1) <> ID_1, VALUE_1 + VALUE_2, 0) as V1V2
Resident a
Order by ID_1, ID_2;
DROP Table a;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
To place them together usually the order by statement is used. Then you can do what I've suggested above.
But why do you load the data in such a strange way ? Consider split the tables like this:
Load distinct ID_1, VALUE_1, VALUE_2 ...
Load ID_1, ID_2
Does it meet your requirements ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Leonardo
if(ID_1 <> previous(ID_1), VALUE_1 + VALUE_2 ,0) AS [VALUE_1+VALUE_2];
if the previous ID_1 is different to the ID_1 that you are reading, means that is the first occurrence, you should sort by ID_1 if you aren't sure if the data is sort by this field.
Hope it helps!
Best regards!
Jonathan
Remember to mark as answered if this is what you looking for!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Leonardo
if(ID_1 <> previous(ID_1), VALUE_1 + VALUE_2 ,0) AS [VALUE_1+VALUE_2];
if the previous ID_1 is different to the ID_1 that you are reading, means that is the first occurrence, you should sort by ID_1 if you aren't sure if the data is sort by this field.
Hope it helps!
Best regards!
Jonathan
Remember to mark as answered if this is what you looking for!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Brilliant! thank you!