Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Re: QlikSense Display Similar Records by X Paramet...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
QlikSense Display Similar Records by X Parameter
Good Day!
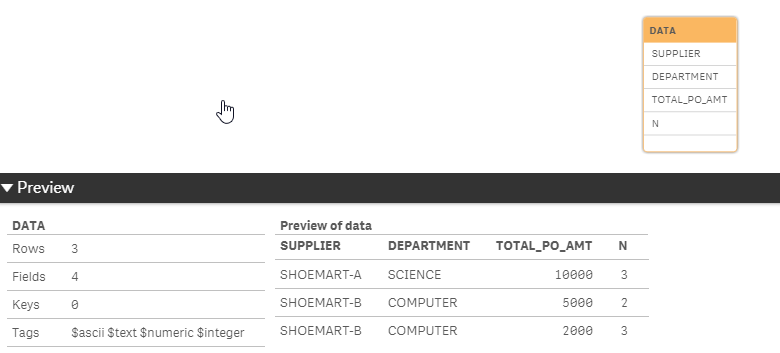
Appreciate if you can help advise on this. I have a PO table (below),
PO_NO SUPPLIER DEPARTMENT AMT TOTAL_PO_AMT
XX9280 SHOEMART-A SCIENCE $5,000 $10,000
XX9280 SHOEMART-A SCIENCE $5,000 $10,000
XX9281 SHOEMART-A SCIENCE $10,000 $10,000
XX9282 SHOEMART-A CHEMISTRY $5,000 $5,000
XX9283 SHOEMART-B COMPUTER $1,000 $5,000
XX9283 SHOEMART-B COMPUTER $4,000 $5,000
XX9284 SHOEMART-B COMPUTER $2,000 $2,000
XX9285 SHOEMART-B COMPUTER $2,000 $2,000
XX9286 SHOEMART-B COMPUTER $2,000 $2,000
XX9287 SHOEMART-B SCIENCE $2,000 $2,000
XX9288 SHOEMART-C CHEMISTRY $5,000 $5,000
XX9289 SHOEMART-C SCIENCE $10,000 $10,000
TASK: I wish to display how many duplicate records (where the SUPPLIER, DEPARTMENT and TOTAL_PO_AMT are the same) on a SUPPLIER standpoint, so I can show the standing as well.
P.S. The PO_NO may appear more than 1 time hence I created a new dimension which calculate the total amount of similar PO_NO.
EXPECTED RESULTS:
SUPPLIER COUNT OF DUPLICATES
SHOEMART-A 2
SHOEMART-B 3
SHOEMART-C 0
Thank you so much!
Eric
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am not sure that the "expected results" should be what you show based on the table you have.
First of all you also have triplicates not only duplicates....
However a load script that will give you a list of the number of similar occurrences higher than 1:
DATA:
LOAD
*
WHERE
N > 1;
LOAD SUPPLIER, DEPARTMENT, TOTAL_PO_AMT, Count(RowNo()) AS N
INLINE [
PO_NO SUPPLIER DEPARTMENT AMT TOTAL_PO_AMT
XX9280 SHOEMART-A SCIENCE 5000 10000
XX9280 SHOEMART-A SCIENCE 5000 10000
XX9281 SHOEMART-A SCIENCE 10000 10000
XX9282 SHOEMART-A CHEMISTRY 5000 5000
XX9283 SHOEMART-B COMPUTER 1000 5000
XX9283 SHOEMART-B COMPUTER 4000 5000
XX9284 SHOEMART-B COMPUTER 2000 2000
XX9285 SHOEMART-B COMPUTER 2000 2000
XX9286 SHOEMART-B COMPUTER 2000 2000
XX9287 SHOEMART-B SCIENCE 2000 2000
XX9288 SHOEMART-C CHEMISTRY 5000 5000
XX9289 SHOEMART-C SCIENCE 10000 10000
] (delimiter is spaces)
GROUP BY
SUPPLIER, DEPARTMENT, TOTAL_PO_AMT
;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am not sure that the "expected results" should be what you show based on the table you have.
First of all you also have triplicates not only duplicates....
However a load script that will give you a list of the number of similar occurrences higher than 1:
DATA:
LOAD
*
WHERE
N > 1;
LOAD SUPPLIER, DEPARTMENT, TOTAL_PO_AMT, Count(RowNo()) AS N
INLINE [
PO_NO SUPPLIER DEPARTMENT AMT TOTAL_PO_AMT
XX9280 SHOEMART-A SCIENCE 5000 10000
XX9280 SHOEMART-A SCIENCE 5000 10000
XX9281 SHOEMART-A SCIENCE 10000 10000
XX9282 SHOEMART-A CHEMISTRY 5000 5000
XX9283 SHOEMART-B COMPUTER 1000 5000
XX9283 SHOEMART-B COMPUTER 4000 5000
XX9284 SHOEMART-B COMPUTER 2000 2000
XX9285 SHOEMART-B COMPUTER 2000 2000
XX9286 SHOEMART-B COMPUTER 2000 2000
XX9287 SHOEMART-B SCIENCE 2000 2000
XX9288 SHOEMART-C CHEMISTRY 5000 5000
XX9289 SHOEMART-C SCIENCE 10000 10000
] (delimiter is spaces)
GROUP BY
SUPPLIER, DEPARTMENT, TOTAL_PO_AMT
;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Petter,
Thank you for your prompt reply. Sorry for my bad english  , I mean to say similar records (SUPPLIER, DEPARTMENT AND AMT]. Honestly, these could be more as I'm checking for X financial years of reports.
, I mean to say similar records (SUPPLIER, DEPARTMENT AND AMT]. Honestly, these could be more as I'm checking for X financial years of reports.
Thank you for the load script count() you've advised earlier. What i did is i declare a new dimension for the similar fields and count the similar in another load script:
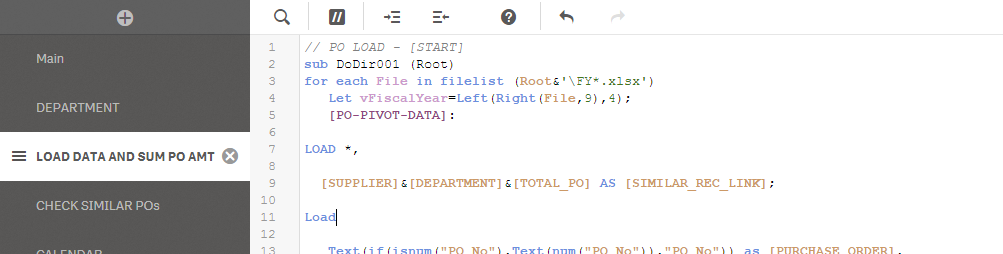
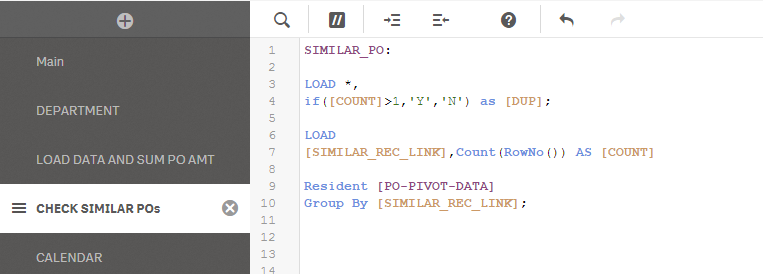
And then, created measures to filter the count I need.
Thank you and have a great day!