Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics
- :
- New to Qlik Analytics
- :
- Re: Values are Multiplying
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Values are Multiplying
So the way my data is structured i had to do a couple of joins. Now the way that the data is coming in, depending on how many attributes each program has, the value is multiplied by that. ex 2 attributes multiplied by 2, 3 attributes multipied by 3. etc. How do I fix this?
Thanks! I have included the load statement! and attatched the data I am using.
LOAD
Program,
Product,
CTA as "Attributes",
"Bias Spring",
"Internal bearing",
"External bearing",
"Backlash Set & Measure",
"# Vane seals",
"# Bolts",
RU,
"Equipment Type",
"Gold Tag #",
Status,
"PO timing",
Supplier,
"# Models",
"# Operators",
"Cycle Time (s)",
"Theoretical OEE (%)",
"Sourced Price",
"Machine capacity",
"Labor cost/unit",
"Capital cost/unit",
"Total cost/unit",
"Lead Time (wks)",
"Warranty (mon)",
"Payment Terms",
"Delivery Terms",
Comments
FROM [lib://VCT Capital Data/2017_02_02_Assembly Lines Benchmarking_MB.xlsx]
(ooxml, embedded labels, table is [VCT (2)])
where CTA = 'CTA';
join
LOAD
Program,
Product,
TA as "Attributes",
"Bias Spring",
"Internal bearing",
"External bearing",
"Backlash Set & Measure",
"# Vane seals",
"# Bolts",
RU,
"Equipment Type",
"Gold Tag #",
Status,
"PO timing",
Supplier,
"# Models",
"# Operators",
"Cycle Time (s)",
"Theoretical OEE (%)",
"Sourced Price",
"Machine capacity",
"Labor cost/unit",
"Capital cost/unit",
"Total cost/unit",
"Lead Time (wks)",
"Warranty (mon)",
"Payment Terms",
"Delivery Terms",
Comments
FROM [lib://VCT Capital Data/2017_02_02_Assembly Lines Benchmarking_MB.xlsx]
(ooxml, embedded labels, table is [VCT (2)])
Where TA = 'TA';
Join
LOAD
Program,
Product,
OPA as "Attributes",
"Bias Spring",
"Internal bearing",
"External bearing",
"Backlash Set & Measure",
"# Vane seals",
"# Bolts",
RU,
"Equipment Type",
"Gold Tag #",
Status,
"PO timing",
Supplier,
"# Models",
"# Operators",
"Cycle Time (s)",
"Theoretical OEE (%)",
"Sourced Price",
"Machine capacity",
"Labor cost/unit",
"Capital cost/unit",
"Total cost/unit",
"Lead Time (wks)",
"Warranty (mon)",
"Payment Terms",
"Delivery Terms",
Comments
FROM [lib://VCT Capital Data/2017_02_02_Assembly Lines Benchmarking_MB.xlsx]
(ooxml, embedded labels, table is [VCT (2)])
Where OPA = 'OPA';
join
LOAD
Program,
Product,
MPL as "Attributes",
"Bias Spring",
"Internal bearing",
"External bearing",
"Backlash Set & Measure",
"# Vane seals",
"# Bolts",
RU,
"Equipment Type",
"Gold Tag #",
Status,
"PO timing",
Supplier,
"# Models",
"# Operators",
"Cycle Time (s)",
"Theoretical OEE (%)",
"Sourced Price",
"Machine capacity",
"Labor cost/unit",
"Capital cost/unit",
"Total cost/unit",
"Lead Time (wks)",
"Warranty (mon)",
"Payment Terms",
"Delivery Terms",
Comments
FROM [lib://VCT Capital Data/2017_02_02_Assembly Lines Benchmarking_MB.xlsx]
(ooxml, embedded labels, table is [VCT (2)])
Where MPL = 'MPL';
Join
LOAD
Program,
Product,
EOL as "Attributes",
"Bias Spring",
"Internal bearing",
"External bearing",
"Backlash Set & Measure",
"# Vane seals",
"# Bolts",
RU,
"Equipment Type",
"Gold Tag #",
Status,
"PO timing",
Supplier,
"# Models",
"# Operators",
"Cycle Time (s)",
"Theoretical OEE (%)",
"Sourced Price",
"Machine capacity",
"Labor cost/unit",
"Capital cost/unit",
"Total cost/unit",
"Lead Time (wks)",
"Warranty (mon)",
"Payment Terms",
"Delivery Terms",
Comments
FROM [lib://VCT Capital Data/2017_02_02_Assembly Lines Benchmarking_MB.xlsx]
(ooxml, embedded labels, table is [VCT (2)])
Where EOL = 'EOL';
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey stalwar1 gwassenaar hic - something you guys can take a look at and make a suggestion on for Ariana?
Mike Tarallo
Qlik
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Perhaps just load the main table as is, but without the attributes columns. So no joining or concatenating. And then create a separate Attributes table with the program and product fields and the attributes. That second table can be created with a CrossTable load:
Attributes:
CrossTable(Attribute, Value,2)
LOAD
Program,
Product,
CTA,
TA,
OPA,
MPL,
EOL
FROM
[LIB://VCT Capital Data/2017_02_02_Assembly Lines Benchmarking_MB.xlsx]
(ooxml, embedded labels, table is [VCT (2)])
;
This will create a synthetic key because the fields Program and Product will exist in both tables. This synthetic key is not a problem and does not need to be removed. But if you want you can create a new key field in both tables based on the Program and Product fields, i.e. autonumber(Program & '|' & Product) as NewKeyField, and use that new key field to associate the two tables. You can then drop the Program and Product fields from for example the new Attributes table.
talk is cheap, supply exceeds demand
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Not sure if changing the data model is a problem here, but an expression like this might help also
Sum(Aggr(Sum(DISTINCT [Sourced Price]), Program))
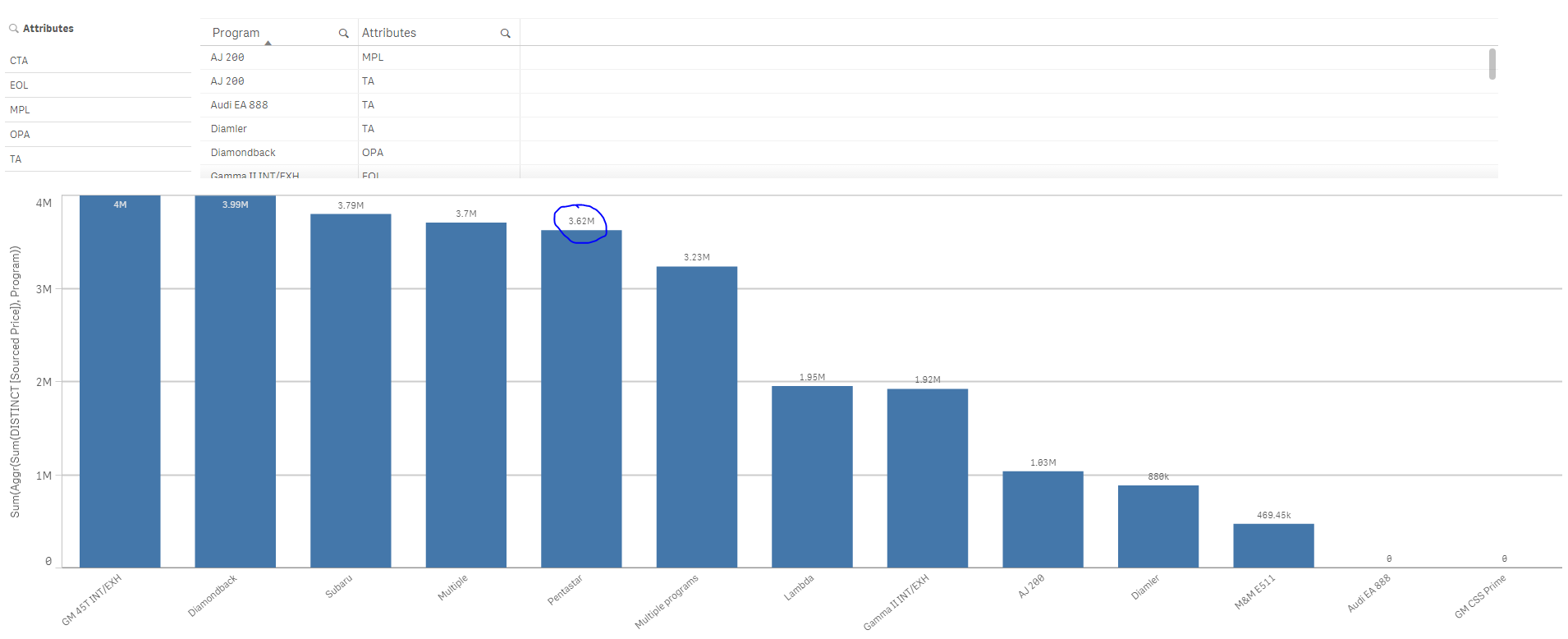
But if there is an option to fix the data model, I would rather fix the data model to avoid the unnecessary use of Aggr() function throughout the application.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am also trying to avid that, as it won’t just be me using the application eventually it will be used across our company.
Thanks
Ariana
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Then look into gwassenaar's solution 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Ariana - just to follow up - Sunny and Gysbert are our resident superstar MVPs in the Qlik Community as you can see from their badges next to their avatars. The suggestions we provided are the best ones available for this current situation. As you can see, you can either use the data as is and let Qlik work around the "un-proper data structure" (so to speak) using various expressions (SET Analysis - AGGR, etc) - are you can make a proper data model out of it using some scripting in the data load editor. Please note - either way Qlik can make it happen - we just need to find some common ground that works for you. The situation you are experiencing is due to the format that your data is in. Since you are new to the Qlik Community - are you evaluating Qlik - do you need additional assistance going forward? Please let us know. we are happy to help.
When applicable please mark the appropriate replies as CORRECT. This will help community members and Qlik Employees know which discussions have already been addressed and have a possible known solution. Please mark threads as HELPFUL if the provided solution is helpful to the problem, but does not necessarily solve the indicated problem. You can mark multiple threads as HELPFUL if you feel additional info is useful to others.
Regards,
Michael Tarallo (@mtarallo) | Twitter
Qlik
Mike Tarallo
Qlik
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This seems to of solved my problem, for now anyway!! Thank you!
Ariana Ford
- « Previous Replies
-
- 1
- 2
- Next Replies »