Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- Remove duplicates in Resident
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Remove duplicates in Resident
Hi people!!
Iam trying to remove duplicates in a resident statement with no success.
There is another way to achieve this?
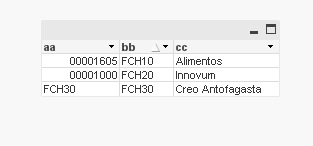
Here i have the the data :
| aa | bb | cc |
| FCH20 | FCH20 | Innovum |
| FCH30 | FCH30 | Creo Antofagasta |
| FCH10 | FCH10 | Alimentos |
| 00001000 | FCH20 | Innovum |
| 00001605 | FCH10 | Alimentos |
NOTE : I want to remove in base of a column called bb.. ( i want to know if it is possible)
My script:
area_grupoceco:
LOAD Distinct
Area_ceco_PEP as aa,
@nombre_area_ceco as bb,
DescripcionArea as cc
Resident Area;
Mensaje editado por: Ivan Diaz
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you want to keep only the records with first occurence of bb value, you can use NOT EXISTS:
area_grupoceco:
LOAD Distinct
Area_ceco_PEP as aa,
@nombre_area_ceco as bb,
DescripcionArea as cc
Resident Area
WHERE NOT EXISTS(bb,@nombre_area_ceco);
assuming that field bb is not already existing in a different table (loaded before area_grupoceco).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
And what is your expected result? What do you count as duplicate?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't see any duplicate records in the data you posted. Every record has a unique combination of field values.
talk is cheap, supply exceeds demand
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
what's the expected result and why?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please explain with more details
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
i updated my question
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you want to keep only the records with first occurence of bb value, you can use NOT EXISTS:
area_grupoceco:
LOAD Distinct
Area_ceco_PEP as aa,
@nombre_area_ceco as bb,
DescripcionArea as cc
Resident Area
WHERE NOT EXISTS(bb,@nombre_area_ceco);
assuming that field bb is not already existing in a different table (loaded before area_grupoceco).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Area:
LOAD
aa,
bb,
cc
FROM
[https://community.qlik.com/thread/177501?sr=inbox&ru=15823]
(html, codepage is 1252, embedded labels, table is @1);
area_grupoceco:
NoConcatenate
LOAD
aa,
bb,
cc
Resident Area
where Previous(bb) <> bb // only load the first bb
order by bb, aa;
DROP Table Area;