Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Data Parsing.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Data Parsing.
Hi
I have three columns ID,Range,Definition In source file. I need to parse "definition" column data. I'm wondering how can we parse dynamically.
Data sample
Source data:
Load Inline [ ID,Range,Definition
X1,1-6,Very Strong(1),Strong(2),Moderate(3),Week(4),Very Week(5),N/A(6)
X2,1-4,Strong(1),Moderate(2),Week(3),N/A(4)
...
]
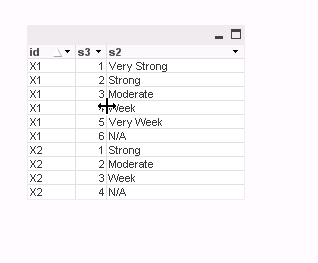
Is it possible to Parse data to below format?
X1 1 Very Strong
X1 2 Strong
X1 3 Moderate
X1 4 Week
X1 5 Very Week
X1 6 N/A
X2 1 Strong
X2 2 Moderate
X2 3 Week
X2 4 N/A
...
Thanks in advance..
Stev
- Tags:
- new_to_qlikview
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
y:
load
id,
if(SubStringCount(s1, '(')=2, left(s1, Index(s1, '(', 2) -1), left(s1, Index(s1, '(', 1) -1) ) as s2,
if(SubStringCount(s1, '(')=2, purgechar(right(s1, len(s1) - Index(s1, '(', 2)), ')'),
purgechar(right(s1, len(s1) - Index(s1, '(', 1)), ')') ) as s3;
load
id,
SubField(definition, ',') as s1;
load
*,
SubField(row, ',', 1) as id,
SubField(row, ',', 2) as range,
right(row, len(row) - Index(row, ',', 2)) as definition ;
Load * Inline [
row
X3,1-5, Always (91-110%) (1), Frequently (70-90%) (2), About Half (30-69%) (3), Rarely (10-29%) (4), Never (0-9%) (5)
X1,1-6,Very Strong(1),Strong(2),Moderate(3),Week(4),Very Week(5),N/A(6)
X2,1-4,Strong(1),Moderate(2),Week(3),N/A(4)
] (delimiter is '|') ;
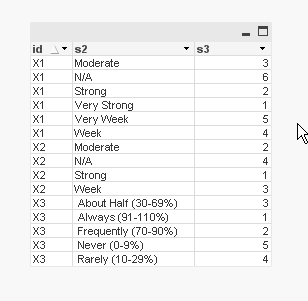
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
RESULT
SCRIPT
load
id,
left(s1, Index(s1, '(') -1) as s2,
purgechar(right(s1, len(s1) - Index(s1, '(')), ')') as s3;
load
id,
SubField(definition, ',') as s1;
load
*,
SubField(row, ',', 1) as id,
SubField(row, ',', 2) as range,
right(row, len(row) - Index(row, ',', 2)) as definition
;
Load * Inline [
row
X1,1-6,Very Strong(1),Strong(2),Moderate(3),Week(4),Very Week(5),N/A(6)
X2,1-4,Strong(1),Moderate(2),Week(3),N/A(4)
] (delimiter is '|') ;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your script it works for above example. Its not working for below data set..
Always (91-110%) (1), Frequently (70-90%) (2), About Half (30-69%) (3), Rarely (10-29%) (4), Never (0-9%) (5)
Output should look like
Always (91-110%) 1
Frequently (70-90%) 2
About Half (30-69%) 3
Rarely (10-29%) 4
Never (0-9%) 5
As we are looking for Index ('(') it looking for first occurrence . So out put is coming as
Always 0-9%(5
Rarely 10-29%(4
About Half 30-69%(3
and so on..
How can we correct this issue.
Thanks,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
y:
load
id,
left(s1, Index(s1, '(', 2) -1) as s2,
purgechar(right(s1, len(s1) - Index(s1, '(', 2)), ')') as s3;
load
id,
SubField(definition, ',') as s1;
load
*,
SubField(row, ',', 1) as id,
SubField(row, ',', 2) as range,
right(row, len(row) - Index(row, ',', 2)) as definition
;
Load * Inline [
row
X3,1-5, Always (91-110%) (1), Frequently (70-90%) (2), About Half (30-69%) (3), Rarely (10-29%) (4), Never (0-9%) (5)
] (delimiter is '|') ;
//X1,1-6,Very Strong(1),Strong(2),Moderate(3),Week(4),Very Week(5),N/A(6)
//X2,1-4,Strong(1),Moderate(2),Week(3),N/A(4)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
load
ID,
(MinValue+IterNo()-1) as Number ,
Definition,
subfield(subfield(Definition,',',(MinValue+IterNo()-1)),'('&(MinValue+IterNo()-1)&')',1) as Value
While MinValue+IterNo()-1 <=MaxValue;
load
ID,
SubField(Range,'-',1) as MinValue,
SubField(Range,'-',2) as MaxValue,
Definition as Definition;
load SubField(row,',',1) as ID,
SubField(row,',',2) as Range,
right(row, len(row) - Index(row, ',', 2)) as Definition;
Load * Inline [
row
X1,1-6,Very Strong(1),Strong(2),Moderate(3),Week(4),Very Week(5),N/A(6)
X2,1-4,Strong(1),Moderate(2),Week(3),N/A(4)
X3,1-5,Always (91-110%) (1), Frequently (70-90%) (2), About Half (30-69%) (3), Rarely (10-29%) (4), Never (0-9%) (5)
] (delimiter is '|') ;

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Table:
LOAD *,
mid(Definition,1,Index(Definition,'(',-1)-1) as String1,
PurgeChar(mid(Definition,Index(Definition,'(',-1)+1),')') as String2;
LOAD ID,
Range,
SubField(String,',') as Definition;
load
Data,
SubField(Data, ',', 1) as ID,
SubField(Data, ',', 2) as Range,
mid(Data,Index(Data,',', 2)+1) as String
;
Load * Inline [
Data
X1,1-6,Very Strong(1),Strong(2),Moderate(3),Week(4),Very Week(5),N/A(6)
X2,1-4,Strong(1),Moderate(2),Week(3),N/A(4)
X3,1-5,Always (91-110%) (1), Frequently (70-90%) (2), About Half (30-69%) (3), Rarely (10-29%) (4), Never (0-9%) (5)
] (delimiter is '') ;
Please see the attached
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
y:
load
id,
if(SubStringCount(s1, '(')=2, left(s1, Index(s1, '(', 2) -1), left(s1, Index(s1, '(', 1) -1) ) as s2,
if(SubStringCount(s1, '(')=2, purgechar(right(s1, len(s1) - Index(s1, '(', 2)), ')'),
purgechar(right(s1, len(s1) - Index(s1, '(', 1)), ')') ) as s3;
load
id,
SubField(definition, ',') as s1;
load
*,
SubField(row, ',', 1) as id,
SubField(row, ',', 2) as range,
right(row, len(row) - Index(row, ',', 2)) as definition ;
Load * Inline [
row
X3,1-5, Always (91-110%) (1), Frequently (70-90%) (2), About Half (30-69%) (3), Rarely (10-29%) (4), Never (0-9%) (5)
X1,1-6,Very Strong(1),Strong(2),Moderate(3),Week(4),Very Week(5),N/A(6)
X2,1-4,Strong(1),Moderate(2),Week(3),N/A(4)
] (delimiter is '|') ;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi
have you managed to solve your problem?
Sasi