Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Filtering on Pre Calculated Data
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Filtering on Pre Calculated Data
Hi,
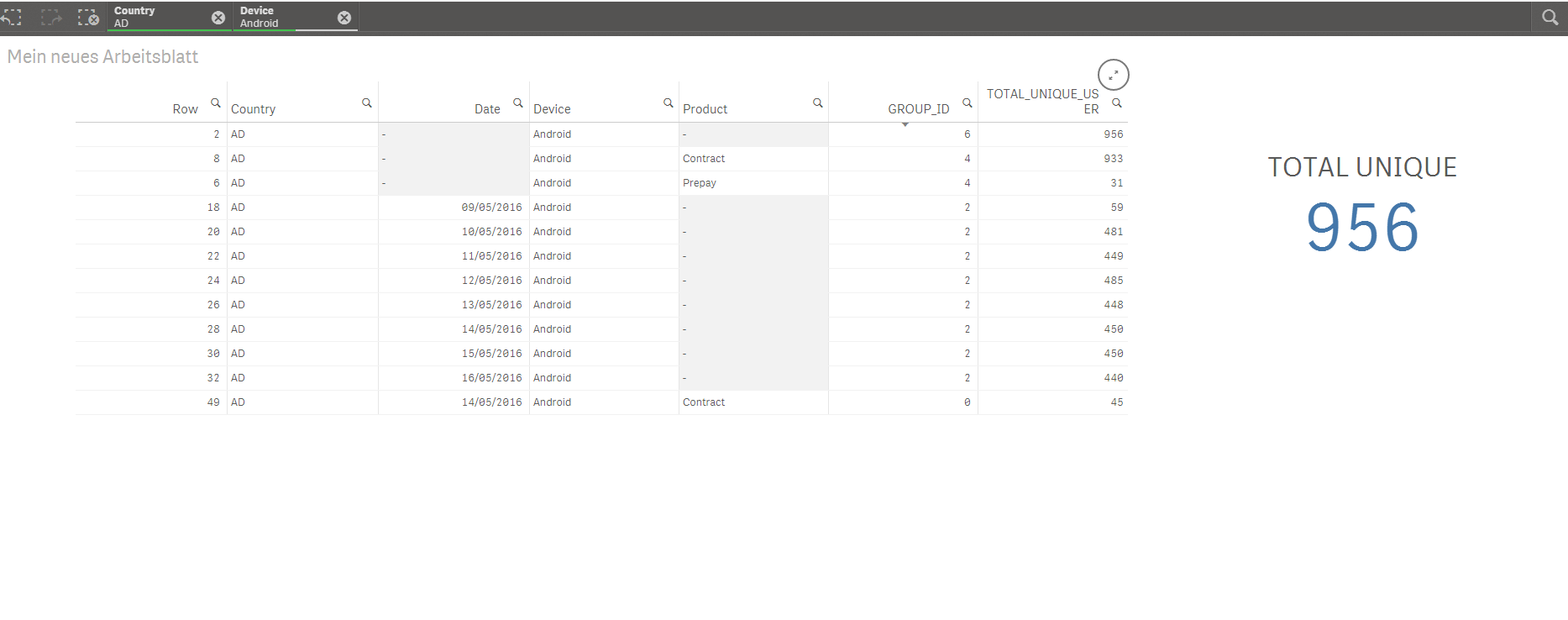
I'm new to Qlik and would like to know how I can view the following data created via a GROUPING SETS statement in SQL. This was used because there are many-to-many relationships between the dimensions.
If you're not familiar with GROUPING SETS data, the first row below totals the unique users for one dimension (Country) and the other rows totals the unique users for two dimensions (Country and Device). This is because some users may have more than one device.
| Country | Device | Total Unique Users |
|---|---|---|
| FRANCE | NULL | 50,000 |
| FRANCE | iOS | 26,000 |
| FRANCE | Android | 25,000 |
I want the user who selects Country=FRANCE as the only filter to return 50,000 unique users and not a sum of all rows containing Country=FRANCE.
How is this best achieved in Qlik? Or should I not be using precalculated fields at all in Qlik, and instead use the user level data (what happens if this is very large)?
Thanks
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Attaching the sample for you to review
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
edit: Sunny is always faster in creating sample apps...
But his expression should also work in Sense
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jones, as per my understanding your source table itself have rolling totals for each dimension combinations. In your requirement, I guess your looking only for Total value for the Country.
So while loading the data, add another flag field to identify the row belongs to which level of dimension its belongs too and use the flag field in your set analysis.
Its easy for your DWH team add the another flag field to table or you can Identify based on the null values on your dimension fields.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jones, you already have GroupID filed to identify the data level belongs to which dimensions. GroupID 7 belongs to Country so you can simply use it.
Expression:
Sum({<{GroupID={7}}>}Total_unique_Users)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the responses,
The issue I have now is what I do if a user wants to select more than one category per field (e.g. selecting both "Android" and "iOS" should return the overall total, similarly for selecting all dates).
Looks like a redesign of the underlying structure so it's a new discussion, unless someone has any initial thoughts?
My thoughts are that the difficulty would lie in when users select part of the categories, e.g. select two dates. The existing data table will not contain the unique count of users across both these dates. This is why using the user-level raw data is perhaps unavoidable 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Right.
&
Right.
(I mean, please create a new thread if you have new questions / requests. And yes, I think you would need to go down to higher granularity of your raw data if you want to be able to get the DISTINCT IDs of your raw data.)
- « Previous Replies
-
- 1
- 2
- Next Replies »