Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Help formatting source file on script load
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Help formatting source file on script load
I'm reading in a file that's in a non-ideal format. The left-most field contains a row with a phone number immediately followed by a corresponding user name. The data associated with the name/number is on the row containing the number (as shown below).
| Field_1 | Some_Data_1 | Some_Data_2 |
|---|---|---|
| 313.212.2112 | 123 | ABC |
| Name_1 | ||
| 212.556.9845 | 234 | THB |
| Name_2 | ||
| 234.564.9875 | 456 | XYZ |
| Name_3 |
I'd like to load the number and then create a new field entitled "UserName" that extracts the name immediately below each number (and then ignore the rest of the blank line). It would be formatted as shown below. Is this possible using cross tables or some other method?
| Field_1 | UserName | Some_Data_1 | Some_Data_2 |
|---|---|---|---|
| 313.212.2112 | Name_1 | 123 | ABC |
| 212.556.9845 | Name_2 | 234 | THB |
| 234.564.9875 | Name_3 | 456 | XYZ |
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
just an idea
first read rows 1,3, 5, 7; make a field with row number (ID); this is TAB1
then read rows 2, 4, 6, 8, make a field with row number -1 (ID); this is TAB2
you have 2 tables joined by the same ID
Result
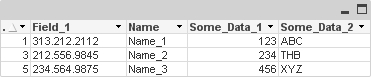
Script
Source:
LOAD * INLINE [
Field_1, Some_Data_1, Some_Data_2
313.212.2112, 123, ABC
Name_1
212.556.9845, 234, THB
Name_2,
234.564.9875, 456, XYZ
Name_3
];
Tab1:
NoConcatenate LOAD RecNo() as ID, * Resident Source where not even(RecNo());
Tab2:
NoConcatenate LOAD RecNo()-1 as ID, Field_1 as Name Resident Source where even(RecNo());
DROP Table Source;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
just an idea
first read rows 1,3, 5, 7; make a field with row number (ID); this is TAB1
then read rows 2, 4, 6, 8, make a field with row number -1 (ID); this is TAB2
you have 2 tables joined by the same ID
Result
Script
Source:
LOAD * INLINE [
Field_1, Some_Data_1, Some_Data_2
313.212.2112, 123, ABC
Name_1
212.556.9845, 234, THB
Name_2,
234.564.9875, 456, XYZ
Name_3
];
Tab1:
NoConcatenate LOAD RecNo() as ID, * Resident Source where not even(RecNo());
Tab2:
NoConcatenate LOAD RecNo()-1 as ID, Field_1 as Name Resident Source where even(RecNo());
DROP Table Source;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good idea. Is there a simple way to only load odd/even rows?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks, I'll give it a go with RowNo() as the parameter.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I suppose Rowno() will works as ID in my script but not in the WHERE condition; when you'll try, let me know; thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well is there a way to do this without editing the source file? I would like this process to be automated - i.e. not necessary to add an ID column each time new data is received.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just as Massimo Grossi said you can use RowNo() / RecNo() to filter odds and even like this:
Table:
LOAD Field1,
Field2,
from Table
where Even( RecNo() );
you can use even() or odd, depending on which rows you need. Also just to verify the results you can add a calculated field in your table as RecNo() as Field
Regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
you can drop ID column at the end
or try this
Source:
LOAD * INLINE [
Field_1, Some_Data_1, Some_Data_2
313.212.2112, 123, ABC
Name_1
212.556.9845, 234, THB
Name_2,
234.564.9875, 456, XYZ
Name_3
];
Tab1:
LOAD
if(even(RecNo()), Field_1, null()) as Field_1_Name,
if(not even(RecNo()), Field_1, peek(Field_1)) as Field_1
Resident Source;
Tab:
NoConcatenate load * Resident Tab1 where len(Field_1_Name)>0;
DROP Table Source;
DROP Table Tab1;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I ended up loading the data as two separate tables and indicated which lines to pull using a WHERE Odd(RecNo()) clause (along with a few other conditions). After loading each table, I joined them, concatenated the joined table to my main table, and dropped the join table. It's a lot of back-end work, but it will be nice to have this autonomous from now on. Thanks for the help!