Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Highlight duplicate rows
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Highlight duplicate rows
Hello,
I want to highlight duplicate rows i.e rows with similar parameters.
Currently, I have added last column which concatenates parameters and highlights duplicates.

What is required:
1. Highlight entire row for duplicate parameters? (not by adding background color in all dimensions of a table)
2. It should work if any new parameter is added. So if parameter4 is added in above chart, and there are duplicate rows including pararmeter4 then it should be automatically highlighted without any code change (actual application has more than 30 parameters and this number is not constant so don't want to waste efforts on maintenance)

Let me know how to achieve this - approach can be different then existing one  (but without data model change)
(but without data model change)
Thank you,
Kinjal
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, I want to find distinctness. But I am renaming values in one of the parameters in the original app  Eg: HONG_KONG, HONGKONG to HONG KONG through calculated dimension.
Eg: HONG_KONG, HONGKONG to HONG KONG through calculated dimension.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do this in the script...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi stalwar1,
I tried this with actual data (10,000+ rows) and duplicate rows were getting highlighted correctly but few unique rows were getting highlighted too.
I am trying to figure out what is wrong but can't find it . I have highlighted one such case:
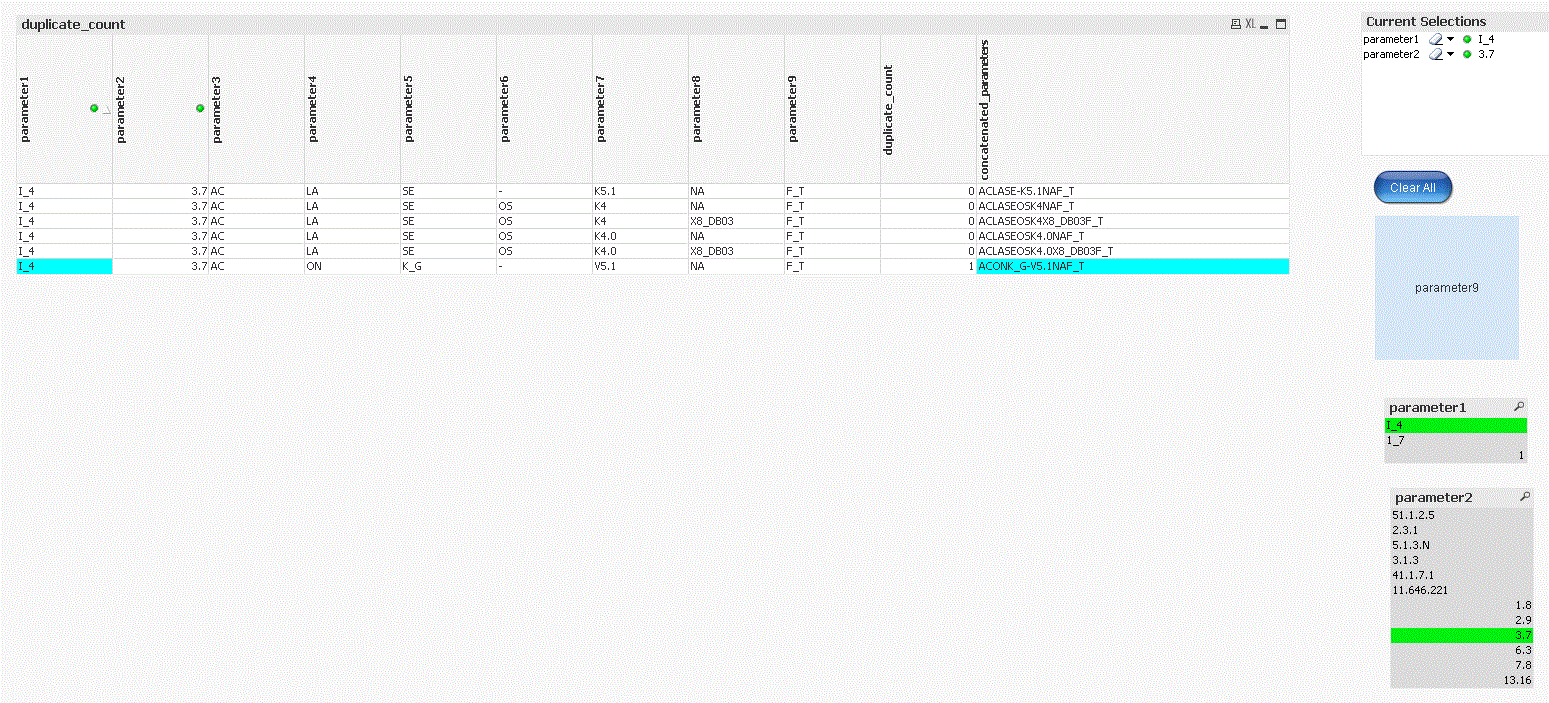
In attached qvw I am trying to highlight duplicates for combination of parameter2 to paramter9.
It would be great if you can help
Thanks,
Kinjal
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am not sure why, but I am seeing two rows for the last row in the chart
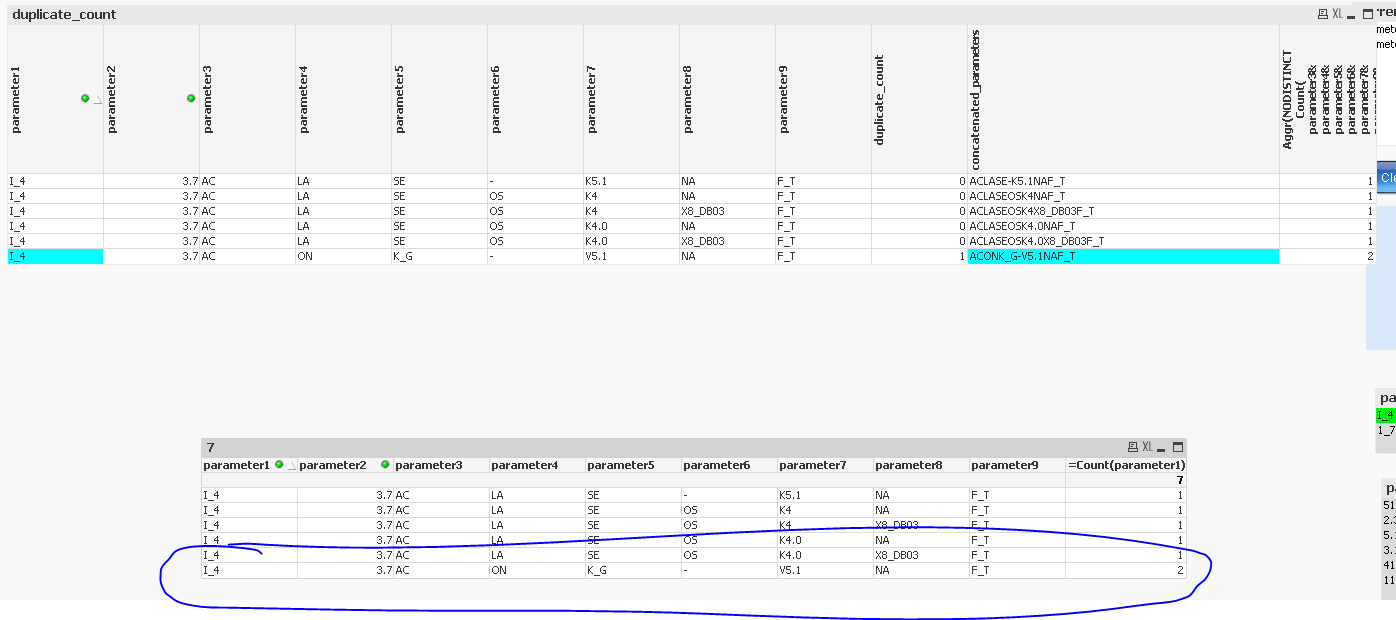
And the Excel you have attached seem to only have 37 rows, whereas the dashboard was reloaded with 360 rows of data... so I can't really see the raw data to know if the data that was reloaded had duplicate or not.
Best,
Sunny
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sunny,
I had reloaded same excel that was attached.
But I have now done inline load to clear the confusion. However still getting same output.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
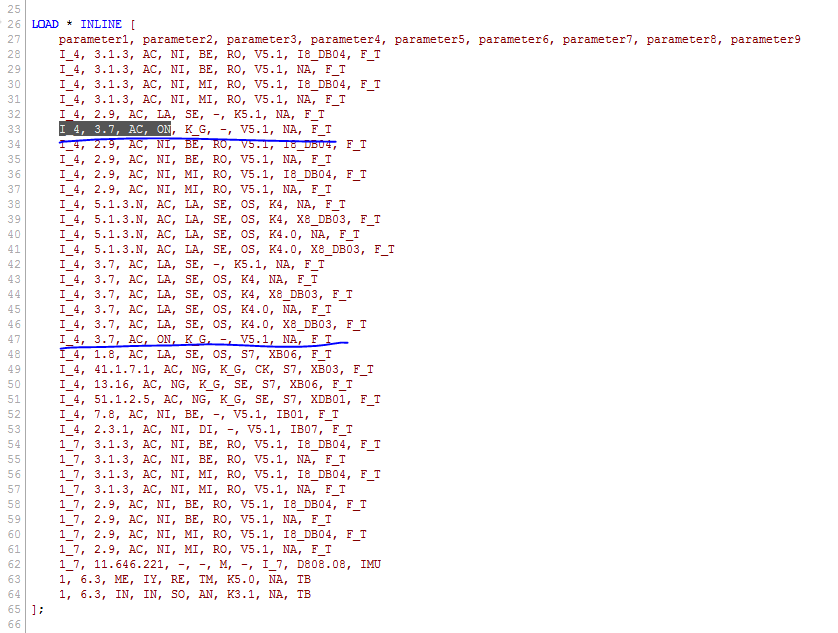
I am not sure I understand your issue because I see two rows in your inline load. Can you tell me why are those not duplicates?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you again
I never analyzed the source data for the problem
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That is usually the first place to look... you might think there are no duplicates, but unless you check the raw data... how can you confirm, right? Keep that in mind for the future my friend
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Right
- « Previous Replies
-
- 1
- 2
- Next Replies »