Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- How to import an unstructured file where the colum...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to import an unstructured file where the columns have different values depending on row identifier?
Basically the delimeter is a $ so very easy to import file.
datagroup:
LOAD
RecNo(), @1,@2,@3,@4,@5,@6,@7,@8,@9,@10,@11,@12,@13,@14,@15,@16,@17,@18,@19,@20,@21,@22,@23,@24,@25,@26,@27,@28,@29,@30,@31,@32,@33,@34,@35,@36,@37,@38,@39,@40,@41,@42,@43,@44,@45,@46,@47,@48,@49,@50,@51,@52,@53,@54,@55
FROM [Test.txt] (delimiter is '$' , no labels);
File layouts is as follow:
Record Identifier Record Type Note
00 File Header One per file
01 Client Header One per client
02 Job Header One per job nested under client
03 Primary Operations One per Primary Operation nested under job
04 Secondary Operations One per Secondary Operation nested under Primary Operation
05 Parts One per part nested under Secondary Operations.
06 Job Trailer One per job
07 Client Trailer One per client
08 File Trailer One per file
I then use a loop to extract the row delimeters and put it into columns:
//exit script;
//import field list and count number of fields
masterfields:
LOAD distinct @1
resident datagroup;
//count no of distinct attributes
let vfieldnos# = fieldvaluecount('@1');
//create pk list
fields:
load distinct RecNo(), @2,@3,@4,@5,@6,@7,@8,@9,@10,@11,@12,@13,@14,@15,@16,@17,@18,@19,@20,@21,@22,@23,@24,@25,@26,@27,@28,@29,@30,@31,@32,@33,@34,@35,@36,@37,@38,@39,@40,@41,@42,@43,@44,@45,@46,@47,@48,@49,@50,@51,@52,@53,@54,@55
resident datagroup;
//set loop to zero
let counter#=0;
//loop through every attribute
for counter#=0 to ($(vfieldnos#)-1)
//createfield names
let vfield = peek('@1',$(counter#),'masterfields');
//join data to pk list
join(fields)
load RecNo(), @2,@3,@4,@5,@6,@7,@8,@9,@10,@11,@12,@13,@14,@15,@16,@17,@18,@19,@20,@21,@22,@23,@24,@25,@26,@27,@28,@29,@30,@31,@32,@33,@34,@35,@36,@37,@38,@39,@40,@41,@42,@43,@44,@45,@46,@47,@48,@49,@50,@51,@52,@53,@54,@55,
@2 as [$(vfield)]
resident datagroup where @1='$(vfield)';
next counter#
//cleanup stage
//RENAME fields USING SchemaFile;
drop table masterfields;
drop table datagroup;
//#######
Now I end up with a file looking like the attachment Extracted File.png
From here on is where I need help since I have to sequentially according to the Record Identifier create multiple loops to created a record per client.
My code is wrong but any assistance will be appreciated.
ClientMaster:
LOAD RecNo(),01,@2,@3
resident fields;
let vfieldnos# = fieldvaluecount('01');
//set loop to zero
let counter#=0;
//loop through every attribute
for counter#=0 to ($(vfieldnos#)-1)
//createfield namesgyv g
let vfield = peek('01',$(counter#),'ClientMaster');
trace$(vfield);
//if vfield=01 then
//Let vNOR=NoOfRows('datagroup');
//Let vOR=Max(RecNo())
//let v@2=Peek('vfield',i-1,'datagroup');
do while isNull(Peek('01',$(counter#)+1,'ClientMaster'))
trace $(vfieldnos#);
trace $(Counter);
//let i=$(counter#);
//do while isNull(Peek('01',i+1,'fields'))
trace($(i));
//trace($(01));
trace$(RecNo());
Clients:
load
// @1 as FieldName,
@2 as ClientCode,
@3 as ClientName
RESIDENT fields
WHERE $(vfield)=01;
join(Clients)
load ClientCode, ClientName //, PreAuthNumber,ClearanceCode
RESIDENT Clients;// Where match(FieldName,$(vfield) );
trace $(vfield);
//counter# = #(counter#) +1
loop //next; //loop;
//endif;
next counter#
//next vfieldnos#
//vfieldnos# = vfieldnos# +1;
//#######
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
please explain your expected result for some of your test rows.
thanks
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marco
I would like to end up with all records linked back to the main client with the correct values per column so I can report on it. I currently cannot link the next row to the previous row per client per job card . The do...while loop gets to complicated or I misunderstand it.
So ideally.
Client ,Job Header , Primary Operations,Secondary Operations ,Parts One per part needs to be tied together with their associated columns.
Their can be multiple jobs per customer as well.
I hope it makes sense.
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Expected layout:
| Client Code | CleintName | Jobcard Number | Multiple Columns as per Record Identifier 02 | Primary Operations | Multiple columns as per Record Identifier 03 | Secondary Operations | Multiple columns as per Record Identifier 04 | Parts 1 | Multiple columns as per Record Identifier 05 | Parts 2 | Multiple columns as per Record Identifier 05 | Job close |
| 18194303 | DEPT OF COMMUNITY SAFETY | 1086768 | 70 | 107 | 391 | 759 | 1 |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
maybe one solution could be:
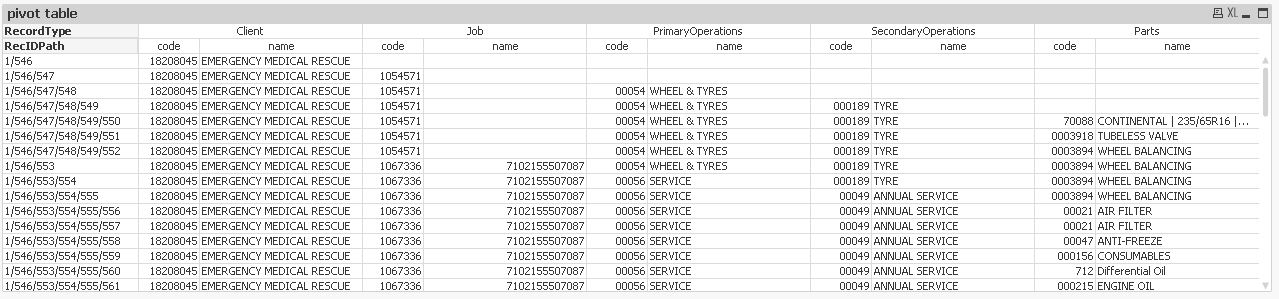
MapRecIdent:
Mapping
LOAD * INLINE [
RecordIdentifier, RecordType
00, File
01, Client
02, Job
03, PrimaryOperations
04, SecondaryOperations
05, Parts
];
tabLinesTemp:
LOAD *,
RowNo() as RecID,
ApplyMap('MapRecIdent',RecordIdentifier) as RecordType
Where RecordIdentifier<6;
LOAD *,
SubField(Line,'$',1) as RecordIdentifier,
SubField(Line,'$',2) as Code,
SubField(Line,'$',3) as Name,
Mid(Line,Index(Line,'$',3)+1) as FieldValues;
LOAD [@1:n] as Line
FROM [https://community.qlik.com/servlet/JiveServlet/download/1368653-301101/Test.txt] (fix, codepage is 1252);
tabRecords:
LOAD *,
Text(If(RecordIdentifier,Left(Peek(RecIDPath)&'/',Index(Peek(RecIDPath)&'/','/',RecordIdentifier))&RecID,RecID)) as RecIDPath,
Text(If(RecordIdentifier,Left(Peek(CodePath)&'/',Index(Peek(CodePath)&'/','/',RecordIdentifier))&Code,Code)) as CodePath,
Text(If(RecordIdentifier,Left(Peek(NamePath)&'@',Index(Peek(NamePath)&'@','@',RecordIdentifier))&Name,Name)) as NamePath
Resident tabLinesTemp;
DROP Table tabLinesTemp;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marco
Thanks I think this is a brilliant solution.
Just one last question please. I have processed a bigger file which gives interesting results . My assumption is that the file construct is not consistent since I stepped through part of it.
can you pls confirm my assumption or am I missing something?
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
yes, you are right.
This extended file includes blank rows and rows starting with a dot.
Changing the script line
Where RecordIdentifier<6;
into
Where RecordIdentifier>=0 and RecordIdentifier<6;
seems to produce better results now:

hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Marco
Definitely.
Appreciate your assistance!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, kOBUS,
A kind reminder, I think you should mark Macro's answer/reply as correct, but not your confirmation/reply/thank you information.
No any offence, but I do notice some new user mark their reply as "Correct Answer" several times in the last few weeks. I understand you are new and may not understand how it works, but I think it is better to point this out.
Zhihong
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bonjour
JE DOIS MODIFER LE NOM DE LA TABLE DANS L'ASSISTANT: au lieu de 31.12.2017. je souhaite le nom du fichier qui s'appelle :CRD.
Voir le fichier ci-joint .
Pouvez vous m'aider
merci