Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- How to load only a section of .cvs file (2)
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to load only a section of .cvs file (2)
Hi,
I' have to read a directory with .cvs file.
My goal is to read every file and estract only the section "Daily Usage" from every file. The no.line position of the "Daily Usage" section is variable.
In a previus discussion https://community.qlik.com/message/1230058#1230058 ( thanks mwoolf) we find a solution to estract the "Summary" section, but I have some problem to extend the solution for the section "Daily Usage"
Some file attached to test.
Thanks to help me
Enrico
- Tags:
- qlikview_scripting
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
tmp:
LOAD
rowno() as id,
FileBaseName() as filebasename,
if(WildMatch(@1, '"Summary*'), 'S',
if(WildMatch(@1, '"Daily Usage*'), 'D',
peek('rowtype'))) as rowtype,
replace(@1, '"', '') as row
FROM
Test_partial_read_?.csv
(txt, utf8, no labels, delimiter is '\t', no quotes);
tmp2:
NOCONCATENATE LOAD
*,
SubField(row, ',', 1) as PartnerID,
SubField(row, ',', 2) as PartnerName
/* add the other fields */
RESIDENT tmp
WHERE not WildMatch(row, 'Summary*', 'Daily*', 'Partner*');
DROP TABLE tmp;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I dont know if this helps, but try these settings in wizard
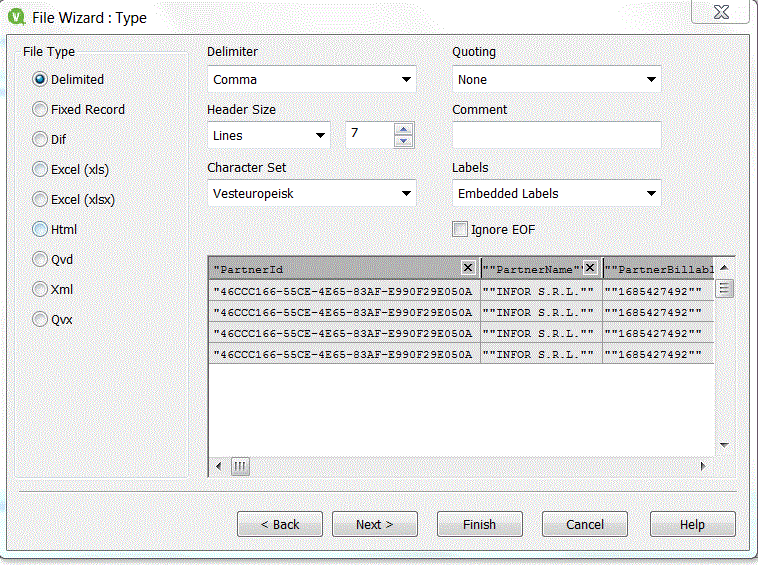
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
tmp:
LOAD
rowno() as id,
FileBaseName() as filebasename,
if(WildMatch(@1, '"Summary*'), 'S',
if(WildMatch(@1, '"Daily Usage*'), 'D',
peek('rowtype'))) as rowtype,
replace(@1, '"', '') as row
FROM
Test_partial_read_?.csv
(txt, utf8, no labels, delimiter is '\t', no quotes);
tmp2:
NOCONCATENATE LOAD
*,
SubField(row, ',', 1) as PartnerID,
SubField(row, ',', 2) as PartnerName
/* add the other fields */
RESIDENT tmp
WHERE not WildMatch(row, 'Summary*', 'Daily*', 'Partner*');
DROP TABLE tmp;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I can see that this wont be good enough
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Perfect!!
It's a valid solution for the "Summary" section and "Daily" section too.
Thanks! Grazie!
Enrico