Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Key field generation methods comparison
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Key field generation methods comparison
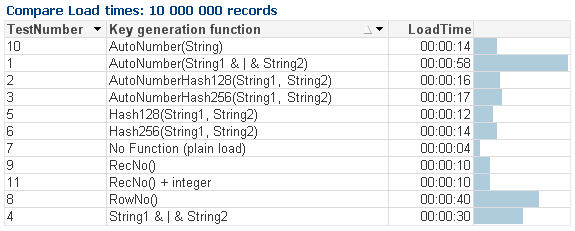
There are many ways to create key fields in data model. I made some tests to better understand speed / performance impact of each method. The variation is quite significant, so the choice is especially important when working with large data volumes.
The test is based on 10M rows of random data which is generated in the start of script and then loaded into another table using Resident Load while generating the key field. I also included counter functions RowNo and RecNo and ’No Function load’ for reference.
Interesting findings:
- Combining strings with ’&’ is extremely heavy on resources. Due to this Autonumber with combining strings is the worst performer (test number 1).
- Autonumber on a fixed string of same length is fast, though (test number 10).
- Hash functions are much faster than combining strings.
- There is no significant performance difference between Hash128 and Hash256.
- RowNo is surprisingly slow (test no. 8). RecNo is 4 times faster.
RowNo and RecNo are different functions by nature but to gain speed, *in some situations* you could use RecNo or ’RecNo + integer’ instead of RowNo. The latter was meant for concatenated tables – instead of ’RowNo() as RowID’, count existing rows before concatenation (Let rowcount = NoOfRows(NewTable) ) and inside concatenate load use ’RecNo() + $(rowcount) as RowID’.
Attached screenshot of the test results (QV 12.10 SR8 on Win7, quad core i5 @ 2.5 GHz, 8 GB RAM), and the QVW.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
i wanted to do it ! very useful, thanks !!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tanel, thanks for sharing the tests. I'm also surprised by the RowNo() performance.
Advantages of Hash() over Autonumber[Hash]() can also be that it can be used on incremental loads, disavantage is that it creates a string, not a number.
Other advantage of AutoNumber() is that it created a sequential integer.
Autonumber() Key Fields and Sequential Integer Optimization | Qlikview Cookbook
(Waiting for experts thoughts on this tests)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Tanel,
Thank you for cataloging the key field generation techniques, and evaluating their comparitive performances, this is a useful collection that will be used for future reference.
There's an additional element could be added to evaluating technique options, and that is lineage. Very often there is a need to return to the source data itself and view the before/after effects of loading & transformation. This analysis could make note of which techniques can be set to correlate to matching actual rows from the input source(s).
A few examples:
The RecNo() feature is keyed to match back to a specific row in a sourcing spreadsheet. (However, this excercise becomes more complicated & requires a little more stridency when the spreadsheet header or body of data is allowed to contain varying amounts of fully empty rows)
RecNo()
The input is coming from a series of input files, and row tracing now must not only track the input row in the file, but which of many possible input files contributed the row (for example, the second of a series of many spreadsheet inputs might concatenate the 51st row to the QlikView table, but this 51st row originates from the 1st row of the 2nd input spreadsheet. Which row id is correct?)
FileID + RecNo()
The input is pulling from multiple tabs, across multiple spreadsheets (hierarchy qualifying layers continue to be added on, till you get a near parallel of Database.Schema,Table.Row)
FileID + TabID + RecNo()
And then there are cases where the flat-files become of such size (> GB's) that most text editors become unable to even open the file and allow manual perusal to the rows in question. In this case, the RecNo() keying needs to be precise enough to allow other tools capable of extracting specific rows from a large file, to find the match and pull it out for verification.
(Autonumber will definitely produce a "leaner" key, but won't help when making raw data to post-scripting verification, whereas incorporating original verbatim elements of the original row into the keying systems help ensure you're dealing with the correct match. Also, Autonumber resets on a load by load basis, and very often creates confusion when it is stored to QVD and attempts are made to "reuse" an older Autonumber. Techniques that build keys off of static elements of the original row should be consistently identifiable across the full existence of the application, and very often that is worth a trade-off in performance.
In personal experience, design has often started off with "inefficient" keying systems that ensure the raw data to Row ID tagging correlation is sound, then after the ETL sequence is tested & trustworthy, those inefficient keys are replaced with better performing ones in final design form.
)
The paramount attribute for these latter mentioned keying systems, not hinging so much on performance, but on the necessity of being able to complete the audit trail between source to end-usage.
Hope you don't mind the added suggestion. Thank you for putting this together, will definitely make use of it. ~E
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Evan,
good points for sure.
I agree that load speed shouldn't be the primary concern for app development.
Actually, until performance isn't critical, I prefer to leave full text keys like ItemID_WarehouseID_YYMMDD.
The benefits are obvious:
- easy to understand
- easy to debug
- can be reused across datamodels
- can be decoded to original values
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Very useful, thanks for sharing
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Tanel,
thank you very much for sharing. Is AutoNumberHash256(string1, string2) and Hash256 really a key generator? Hash collisions will destroy the uniqueness of the key.
Kind regards,
Herbert
- Tags:
- hash collision