Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- LOOP THROUGH FILES IN FOLDER AND REMOVE CHARACTERS...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
LOOP THROUGH FILES IN FOLDER AND REMOVE CHARACTERS FROM FIELD NAMES AND DATA
Hi All,
i need some help with getting some files stored to QVD but removing some characters from the data and field names.
there are over 500 files in total, i can do it manually but it will be very time consuming as each file has different field names ( i can't get * to work).
basically the field names are in the format of
@@FIELD1@@
@@FIELD2@@
@@FIELD3@@
etc
and the data held against each field is in the same format, i.e...
@@FIELD1@@
@@VALUE1@@
@@VALUE2@@
@@VALUE3@@
etc
also, the last field in in each file has a SPACE before the last 2@@ i.e.
[@@FIELD40@@ ]
the space also needs to be removed.
I have attached an example, can anyone help please?
- Tags:
- qlikview_scripting
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't really understand, your qvw does seem to work. What is the issue?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, yes the sample i uploaded does work. what i am asking though is there a quick way of doing the same thing for over 500 files, all with different fields.
otherwise i have to load each file int the script, perform a find and replace @@ with nothing, remove the space from the last field name and edit the delimiter to @@|@@ manually which will be very time consuming.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That make sense.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can remove the special characters in field values using mapsubstring. Here is an example,
ReplaceMap:
MAPPING LOAD * INLINE [
char, replace
@,
]
;
TestData:
LOAD
*,
MapSubString('ReplaceMap', data) as ReplacedString,
MapSubString('ReplaceMap', data1) as ReplacedString1
;
LOAD * INLINE [
data,data1
@@@AAA@@@,@@123@
@@@BBB@@@,@@345@@@
@CCC@@@,@1111@
@@@DDD@,@@@22@
]
;
I am not sure how we can do for all field names.
Regards,
Sivaraj
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
does anyone have any ideas on how i can do this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Hopkinsc,
Try something like below,
Sub ScanFolder(Root)
For Each FileExtension in 'txt'
For Each FoundFile in FileList( Root & '\*.' & FileExtension)
Data:
LOAD
SubField('$(FoundFile)','\',SubStringCount('$(FoundFile)','\')+1) as FileName,
Trim(Replace (@@CVCRCD@@, '@@','')) as CVCRCD,
Trim(Replace (@@CVDL01@@, '@@','')) as CVDL01,
Trim(Replace (@@CVEC@@, '@@','')) as CVEC,
Trim(Replace (@@CVCDEC@@, '@@','')) as CVCDEC,
Trim(Replace (@@CVCKR@@, '@@','')) as CVCKR,
Trim(Replace (@@CVUSER@@, '@@','')) as CVUSER,
Trim(Replace (@@CVPID@@, '@@','')) as CVPID,
Trim(Replace (@@CVUPMJ@@, '@@','')) as CVUPMJ,
Trim(Replace (@@CVJOBN@@, '@@','')) as CVJOBN,
Trim(Replace ([@@CVUPMT@@],'@@','')) as CVUPMT
FROM
[$(FoundFile)]
(txt, codepage is 1252, embedded labels, delimiter is '|', msq);
Next FoundFile
Next FileExtension
End Sub
Call ScanFolder('C:\Users\Tamilarasu.Nagaraj\Desktop\Test_196312') ;
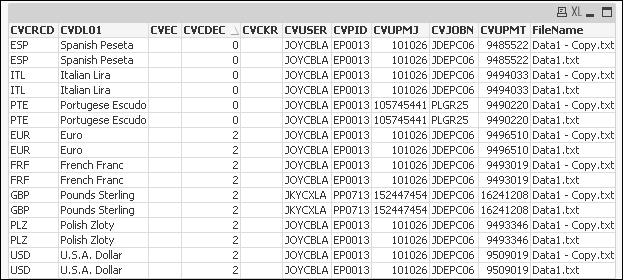
Sample application attached against your data. Let me know.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
The Purgechar and SubField functions might be useful to you:
Currencies:
Load
PurgeChar(SubField(@1,'|',1),'@') as Abbreviation,
PurgeChar(SubField(@1,'|',2),'@') & ' ' & @2 as Currency;
LOAD @1,
@2
FROM
Data1.txt
(txt, codepage is 1252, no labels, delimiter is ' ', msq) Where RecNo()>1;
gives this table:
| Abbreviation | Currency |
|---|---|
| ESP | Spanish Peseta |
| EUR | Euro |
| FRF | French Franc |
| GBP | Pounds Sterling |
| ITL | Italian Lira |
| PLZ | Polish Zloty |
| PTE | Portugese Escudo |
| USD | U.S.A. Dollar |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Andrew / Marco
Thanks for the reply. unfortunately this isnt the answer as the data was provided to me using a custom delimiter of @@|@@ because the data values include pipes. so if i strip out the @ characters and use a pipe as a delimiter then this would cause problems with the pipes that are supposed to be present in the values. (if that makes sense).
What i need is to strip out all @ from the field names, store out and read back in using the @@|@@ delimiter.
unless there is another way where i don't have to read in each file twice.
- « Previous Replies
-
- 1
- 2
- Next Replies »