Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Merge two values
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Merge two values
Hi,
I need to mege two values which are existing in the same field but in last both names are different.
For example:
MyField: These values are coming in the list box
Current Output:
ABC-CDE
ABC-CDEFG
Required Output:
Required output
ABC-CDE
Both should be merge by using great method. Such as using wildmatch etc.
Note: Some times these values are greater then 7 digit
For Example: Current scenario
XYZ-AB-001
XYZ-AB-001-C1
Requried scenario:
XYZ-AB-001
Therefore, I need a method which run in all the scenarios.
regards,
- Tags:
- qlikview
- « Previous Replies
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
maybe changing the b load only, difference with previous script posted is in bold
Sales:
LOAD field, value, len(field) as len
FROM Sales.xlsx (ooxml, embedded labels, table is Sheet1);
b:
load
field,
len,
value,
if(wildmatch(field, peek(fieldgroup) & '*') and len(peek(field))>0, peek(fieldgroup), field) as fieldgroup
Resident Sales
order by field, len;
DROP Table Sales;
c:
load
fieldgroup as field,
sum(value) as value
Resident b
group by fieldgroup;
drop table b;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
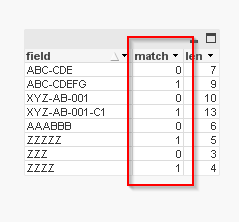
see attachment, 0 in match is for rows you must keep
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Massimo,
Please share me script, expression. I have personal edition therefore I'm not able to open the qvd.
regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
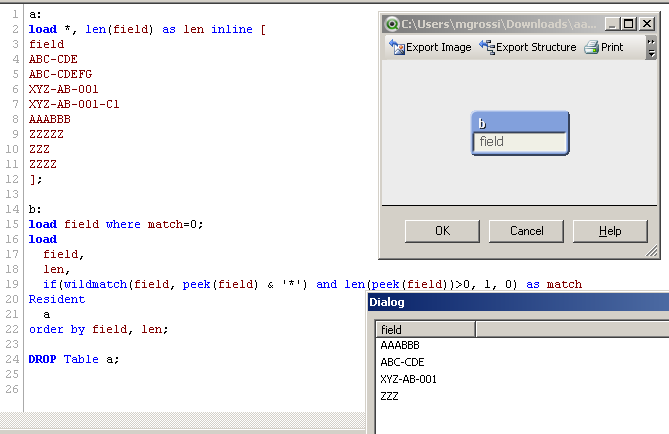
a:
load *, len(field) as len inline [
field
ABC-CDE
ABC-CDEFG
XYZ-AB-001
XYZ-AB-001-C1
AAABBB
ZZZZZ
ZZZ
ZZZZ
];
b:
load
field,
len,
if(wildmatch(field, peek(field) & '*') and len(peek(field))>0, 1, 0) as match
Resident
a
order by field, len;
DROP Table a;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Massimo,
The problem is still there, as you showed in your image there is match and length column. This is not required.
Current Scenario:
ABC-CDE
ABC-CDEFG
XYZ-AB-001
XYZ-AB-001-C1
AAABBB
ZZZZZ
ZZZ
ZZZZ
and Desired output required:
ABC-CDE
XYZ-AB-001
AAABBB
ZZZ
Please help me, to solve this problem.
regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I add the match and len column to show the solution, if you don't want the 2 columns add a preceding load, in bold, to filter values with match = 0 and to just keep one column
a:
load *, len(field) as len inline [
field
ABC-CDE
ABC-CDEFG
XYZ-AB-001
XYZ-AB-001-C1
AAABBB
ZZZZZ
ZZZ
ZZZZ
];
b:
load field where match=0;
load
field,
len,
if(wildmatch(field, peek(field) & '*') and len(peek(field))>0, 1, 0) as match
Resident
a
order by field, len;
DROP Table a;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Massimo,
No effect on the data.
This output is coming
ABC-CDE
ABC-CDEFG
XYZ-AB-001
XYZ-AB-001-C1
AAABBB
ZZZZZ
ZZZ
ZZZZ
instead of required output.
ABC-CDE
XYZ-AB-001
AAABBB
ZZZ
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
are you sure?
I reload the script and I got 4 rows
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
another solution might be:
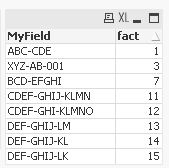
table1:
LOAD * INLINE [
MyField, fact
ABC-CDE, 1
ABC-CDEFG, 2
XYZ-AB-001, 3
XYZ-AB-001-C1, 4
BCD-EFGHI-JKLM-0123, 5
BCD-EFGHI-JKLM, 6
BCD-EFGHI, 7
BCD-EFGHIJKL, 8
BCD-EFGHI-0123, 9
CDEF-GHIJ-KLMNO, 10
CDEF-GHIJ-KLMN, 11
CDEF-GHI-KLMNO, 12
DEF-GHIJ-LM, 13
DEF-GHIJ-KL, 14
DEF-GHIJ-LK, 15
];
Right Join
LOAD MyField Where CountMyField=1;
LOAD MyField, Count(MyField) as CountMyField Group By MyField;
LOAD * Where FieldIndex('MyField', MySubField);
LOAD MyField, Left(MyField,IterNo()) as MySubField
Resident table1 While IterNo()<=Len(MyField);
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Massimo,
I hope this script will give you better understanding, when I'm going to add one more field then nothing is going to be showed, please check.
a:
load *, len(field) as len inline [
field, value
ABC-CDE, 2
ABC-CDEFG, 2
XYZ-AB-001, 3
XYZ-AB-001-C1,3
AAABBB, 4
ZZZZZ, 5
ZZZ, 5
ZZZZ, 5
];
b:
load field where match=1;
load
field,
len,
value,
if(wildmatch(field, peek(field) & '*') and len(peek(field))>0, 1, 0) as match
Resident
a
order by field, len;
DROP Table a;
- « Previous Replies
- Next Replies »