Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Optimization?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Optimization?
Hi,
I am just looking through an app that is supposed to do some Quality-checking on the Background of another app to help in looking for the cause of a potential reload_failure ...
At the same time I am thinking about ways to maybe optimize this.
There is one IF_THEN_clause pretty much at the beginning using >> qvdcreatetime << of a rather large qvd - that takes quite a while - is there any way to get the same effect quicker?
Maybe I can store only the timestamp (>>NOW()) at the time that qvd is saved pretty much at the end of the daily script_run - would that make it faster, if I only load a very small file to check that?
Thanks a lot!
Best regards,
DataNibbler
P.S.: Moreover, this function is, afaIk, only used to decide whether there is such a qvd at all, the actual creation_time is not relevant - this IF_THEN is merely wrapped around a concat_load. That seems like a case of "if I were going there, I wouldn't be starting from here" to me, no?
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks!
There are enough Points where I can have a critical look at potential for optimization - I am just looking at another script where, such as I understand it
- a list of all qvd_files in a Directory is generated
- this list is sorted asc. by filetime
- The ID of the one with the newest filetime (which happens to be the very last one) is extracted
- A statistics_table drawing from that identifies whether there is an up-to-date file in that table (well, there is only one file in the table 😉
- If that is the case, the path to that file is extracted
=> and then the file is loaded.
Oopsie - ah, well, yes, definitely possible and seemingly correct ...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
These "funny" apps - those are Monitoring_apps (we have a herd of those, one for every extract_Job there is). All they do is collect some meta_data on the qvd_files that have been generated, for whatever that is worth ...
Up to now, the qvd's were loaded (optimized) just to Count the nr. of records there is. I replaced that with loading just one field, a >>rowNo()<< - but that does not seem to have shortened their runtime dramatically ... is there a faster way to do that?
Thanks a lot!
Best regards,
DataNibbler
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There are several functions to read meta-data from QVD,
below copied from OL-Help:
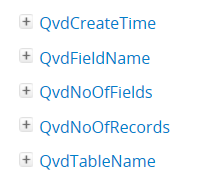
This may help, as they do not open the QVDs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yep - the >> QVDNoOfRecords << might help 😉 I'll see what can be done.
The meaning and importance of all These apps is a bit unclear to me anyway - Monitoring all of the apps seems like a good idea in case several Tasks overlap on the Server and one Fails, that could help with Debugging ... but one app for every Extractor seems a bit over the top ...
Thanks a lot!
- « Previous Replies
-
- 1
- 2
- Next Replies »