Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Partial Reload while avoiding duplicates
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Partial Reload while avoiding duplicates
I have a QV dashboard with 10 tables with millions of rows which are linked by a common column "ID"
I want to run partial reload each day to add in new data from csv files.
However, lets say on Day 1 I load this csv
ID name age hometown
1 John 10 NY
2 Jane NY
3 Jim 23 NY
so as you can see jane's age is missing on day one
on Day 2 (or some day down the road) I now have this CSV to load
ID name age hometown
2 Jane 15 NY
3 Jim 23 NY
4 Jack 55 NY
so basically I want to update the Jane's entry, but atm if i run a partial reload the standard way i end up with duplicate entries.
is there any way to just update entries in a table based during partial reload?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ritvik,
Use incremental load:
Incremental load is of three types:
- Insert Only
- Insert & Update
- Insert, Update, & Delete
INSERT & UPDATE
The INSERT & UPDATE scenario also takes new data from the source but it also pulls in updated records. Additional precautions need to be taken in order to avoid duplicate records. During the load from the QVD, exclude records where there is a match on the primary key. This will ensure that the updated records will not be duplicated.
- Load all NEW and UPDATED data from the data source
- Concatenate this data with a load of only the missing records from the QVD file
- Store the entire table out to the QVD file
Example:
DataTable:
SQL SELECT
PrimaryKey,
A,
B,
C
FROM Table1
WHERE ModifyDate >= $(vDate);
CONCATENATE
LOAD
PrimaryKey,
A,
B,
C
FROM ABC.qvd
WHERE NOT exists (PrimaryKey);
STORE DataTable into ABC.qvd;
Regards
Neetha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thanks for the reply!
Is it possible to do incremental load without using QVDs but CSVs?
Have been finding that during reload QVDs although faster, have been using more memory , and this is my constraint at the moment
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
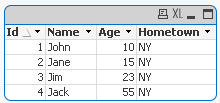
Yes. Loading your sample data using inline load using the script below produces the update correctly:
LOAD * Inline [
Id, Name, Age, Hometown
2,Jane,15,NY
3,Jim,23,NY
4,Jack,55,NY
];
Concatenate LOAD * Inline [
Id, Name, Age, Hometown
1,John,10,NY
2,Jane,,NY
3,Jim,23,NY
]
where not Exists (Id);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
yes the case you explained works
but my case is the other way round. as in some columns have empty fields during an initial load, but then a few days later, i get those fields for the data.
this is loaded first:
Id, Name, Age, Hometown
1,John,10,NY
2,Jane,,NY
3,Jim,23,NY
then this:
Id, Name, Age, Hometown
2,Jane,15,NY
3,Jim,23,NY
4,Jack,55,NY
any way to make this work without using QVDs, but instead CSVs?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi Ritvik,
Its possible to do on csv, first load do full extract and next time onward extract and concatenate to resident load(previously loaded data).
Data1:
LOAD Customer,
[Sales Order ID],
ShipDate,
Product,
Sales,
Quantity
FROM
(biff, embedded labels);
NoConcatenate
Data:
LOAD *
Resident Data1;
Concatenate
LOAD Customer,
[Sales Order ID],
ShipDate,
Product,
Sales,
Quantity
FROM
(biff, embedded labels)
where not Exists([Sales Order ID]);
DROP Table Data1;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thanks for the reply! but does this solve my initial problem?
where some columns have empty fields
but then later in my csv those fields become filled and i want to update those rows?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello, With Partial Reload you can't update the already loaded table data. Either you can replace whole table or add the data. If your latest file have the full data set, simply use partial reload to replace the table.
Otherwise, do full reload with full incremental load.
You can also do incremental load on csv. But I am not sure it will give the better performance.