Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Permutations Math
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Permutations Math
I have created a field called 'Sequence' a 7 character (Upper Case) text field that is made up from the sequence (ascending order) of 7 timestamps that are captured for each record transaction. The timestamps are:
O = Ordered product
G = List product
L = Label Product
C = Collect
A = Arrive Product
P = Prepare Product
R = Report on Product
Depending on the sequence order they are performed a typical Sequence field could look like OGLCAPR or OLGCAPR. My analysis thus far is displayed below:
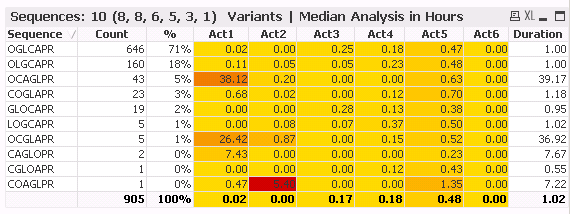
I now want to perform this time analysis above based on distinct combinations of 2 , i.e. Permutations without repetition (n=7, r=2)
List has 42 maximum entries.
OL OG OC OA OP OR LO LG LC LA LP LR GO GL GC GA GP GR CO CL CG CA CP CR AO AL AG AC AP AR PO PL PG PC PA PR RO RL RG RC RA RP
If I take the same table above and apply the MID() function to the Sequence filed I would get the results below.
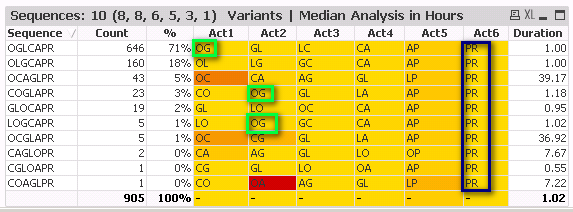
Challenge/Question?
I now want to perform an analysis similar to the above on unique timestamp permutations for example 'OG' occurred 646 + 23 + 5 = 474 times.and PR occurred 905 times. (In the above example I want to analyze the performance of OG regardless of it being performed in step 1 or step 2.) The new analysis would consists of unique permutations, e.g., OG, PR, LO with corresponding Count, % and throughput statistics. Hope this all makes sense. How can this be accomplished in QlikView?
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
awesome solution.
Having millions of records it could improve the performance to use only distinct Sequence values in the link table:
LOAD DISTINCT Sequence, mid(Sequence,IterNo(),2) as Permut, 1 as Count
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This might distort the aggregated count (well, as I've understood the requirements of the analysis).
But you can aggregate the counts:
LOAD Sequence, Permut, count(Sequence) as Count
GROUP BY Sequence, Permut;
LOAD Sequence, mid(Sequence,IterNo(),2) as Permut
RESIDENT DATA
WHILE iterno() <= 6;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Swuehl
You are amazing! The simplification of the interval formula and generating the Permut field is exactly what I am looking for this this analysis.
Below, I took the snippet of code you provided above (not the attached qvw) and with autogenerate set to 1 looked at a single record. There are 2 pieces to the analysis that I am doing:
- Examining the order in which the steps are performed for each record and then calculating the time intervals. This was accomplished with the creation of the Sequence field and the interval fields i1_2… i6_7.
- Generate the Permut fields for each transaction and then calculate the time intervals for each of these. So in the singe record generated below I would now need to calculate the time interval for AL, CG, GR, OC, PO and RA

Requirement 2 still poses a challenge for me. The main table that contain these transaction have over 9 million records and it is growing. The sequence field and the time interval fields can continue to remain in the main table as they now are. In order to perform the analysis on the Permut field, since there will be a 1 to many (6) relationship for each transaction record in the main table, will require a separate table that is created at LOAD time with the time intervals for each Permut per-calculated. I I envision that the Permut table will consist of 3 fields of information, the ID field that ties it back to the main DATA table, the Permut field and the calculated interval time for each Permut.
Does this approach make sense? If yes can you advise on the creation of the Permut table and the calculation for each time interval?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Marco, thank you for you suggestion. For this analysis Distinct can not be used.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sunny, thanks code snippets shared below.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try this for link table generation:
LOAD ID, mid(Sequence,IterNo(),2) as Permut, 1 as Count,
pick(IterNo(), i1_2, i2_3, i3_4, i4_5, i5_6, i6_7) as PermutInterval
RESIDENT DATA
WHILE iterno() <= 6;
edit: to keep the number of distinct values low (this will also save time in the fact and link table), it might be a good idea to round the calculated intervals to a number of decimal places needed for your analysis.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Swuehi, you are a genius, that did the trick! Thanks so much for your help with this post! 
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Regarding..."round the calculated intervals to a number of decimal places needed for your analysis."
Rounding to 2 decimal places is all that is required... can this be accomplished in the script?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sure,
this code is rounding the intervals:
LEFT JOIN (DATA)
LOAD
ID,
Concat(Field, '',Time) as Sequence,
round((min(Time,7)-min(Time,1))*24,0.01) as i1_7,
round((min(Time,2)-min(Time,1))*24,0.01) as i1_2,
round((min(Time,3)-min(Time,2))*24,0.01) as i2_3,
round((min(Time,4)-min(Time,3))*24,0.01) as i3_4,
round((min(Time,5)-min(Time,4))*24,0.01) as i4_5,
round((min(Time,6)-min(Time,5))*24,0.01) as i5_6,
round((min(Time,7)-min(Time,6))*24,0.01) as i6_7
Resident X
Group BY ID;
Leaving the original timestamp fields untouched (though also these could be rounded or maybe even dropped?).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks again! I have learned many things from you through this post!
- « Previous Replies
-
- 1
- 2
- Next Replies »