Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Remove duplicates from Straight Table - Help!
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Remove duplicates from Straight Table - Help!
Hi All,
I have a Straight Table data like this. Need to remove the duplicates from Straight Tabl
| Cust ID | Acc # | Product ID | Price |
| 1 | 81 | 10001 | $10 |
| 1 | 81 | 10002 | $5 |
| 1 | 100 | 10002 | $5 |
| 2 | 45 | 20001 | $7 |
| 2 | 90 | 20001 | $7 |
| 3 | 25 | 30001 | $8 |
| 3 | 25 | 30002 | $6 |
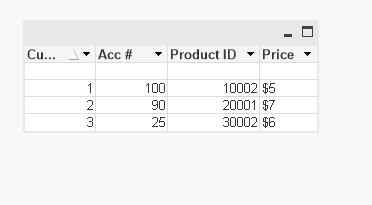
Need to display the Minimum Price for the Maximum Acc #. If the Acc # is same for on Cust ID, then consider the Max Product ID. Output Straight Table will be like below -
| Cust ID | Acc # | Product ID | Price |
| 1 | 100 | 10002 | $5 |
| 2 | 90 | 20001 | $7 |
| 3 | 25 | 30002 | $6 |
Can someone please help here?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please check this
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
you can try this
Source:
LOAD [Cust ID],
[Acc #],
[Product ID],
Price
FROM
[https://community.qlik.com/thread/225921]
(html, codepage is 1252, embedded labels, table is @1);
Final:
NoConcatenate
LOAD *
Resident Source
Where [Cust ID] <> Peek('Cust ID')
Order By [Cust ID], [Acc #] desc, Price ;
DROP Table Source;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I recommed using first sorted value for may be all of the expression (1st one can be avoided)
FirstSortedValue([Acc #], - [Acc #] - [Product ID]/10000) or Max([Acc #])
FirstSortedValue([Product ID], - [Acc #] - [Product ID]/10000)
FirstSortedValue(Price, - [Acc #] - [Product ID]/10000)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Another way to handle it in the script is using Aggregation functions:
Try it - This is bit simpler with no complex functions used.
TAB1:
LOAD [Cust ID],
[Acc #],
[Product ID],
Price
FROM
[https://community.qlik.com/thread/225921]
(html, codepage is 1252, embedded labels, table is @1);
TAB2:
QUALIFY*;
LOAD [Cust ID],
Max([Acc #]) as MAX_ACC,
Max([Product ID]) as MAX_Prod,
Min(Price) as Min_Price
FROM
[https://community.qlik.com/thread/225921]
(html, codepage is 1252, embedded labels, table is @1)
where [Cust ID] <> ''
Group BY [Cust ID]
;
RESULT :
| TAb2.Cust ID | TAb2.MAX_ACC | TAb2.MAX_Prod | TAb2.Min_Price |
|---|---|---|---|
| 1 | 100 | 10002 | 5 |
| 2 | 90 | 20001 | 7 |
| 3 | 25 | 30002 | 6 |