Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Semicolon in Data Source - How to load the dat...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Semicolon in Data Source - How to load the data properly?
Hi guys,
I need your help, if there is anything possible.
The situation is as follows:
I have a csv file as data source which gets updated multiple times a day. The csv file is semicolon seperated. It always contains a fixed set of columns (20 columns). One column is a description. Like twice a week or so it happens that in 2-5 rows the description contains a semicolon in the text.
As I want to automate the whole data loading process you see the point, right? Is there any way or possibility to do not get an error when this happens, caused by the fact that the rows get displaced due to the semicolon in the text. My first idea was to just replace the semicolon seperator with something else when the source exports the csv file, but this is unfortunately not possible.
Is there any way to overcome this?
Thanks guys!
Greetings,
Seb
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks.
I first tried to LOAD * From_Field with embedded labels, but failed doing so.
That's why I had to rename the fields in the end.
Nevertheless, I'm glad it worked.
good night
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Marco, it's acceptable to provide comments in your script 
-Rob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marco,
the outcome looks exactly like that what I need.
It would be nice to add comments in the script or to explain me what the script is actually doing as I cant figure it out properly yet.
But yeah this looks like what I need.
Thanks a lot for your help already!
EDIT: I tested your QVW-File with mine csv. It does not work properly, but probably because my description column is the 5th and not the 3rd column. How can I fix that?
And I saw that it generates a synthetic key. Is that correct?
I would just store table 2 then in a qvd to use it somewhere else right?
And another point is that it does not display the letters ö, ä, ü properly. I already tried to replaced codepage 1252 by utf8 or ansi (which is the same as 1252) but this was not the root cause or I took the wrong charset. Notepad++ says the file is Ansi encoded.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the first table load, Marco is reading your input file in with out parsing the columns, so each line goes into a single field 'line'.
Left([@1:n],Index([@1:n],';',2))&'"'&Mid([@1:n],Index([@1:n],';',2)+1,Index([@1:n],';',SubStringCount([@1:n],';')-16)-Index([@1:n],';',2)-1)&'"'&Mid([@1:n],Index([@1:n],';',SubStringCount([@1:n],';')-16))
He is adding double quotes " around the part in question, to find the correct positions for the double quotes, he is looking for the 2 semicolon counted from the beginning, he knows this will start the third column in the file, the text description. But he does not know how many semicolons are contained in the text. So for the end of the column, he is looking for the 16th semicolon counted from the end.
[edit: see below for the implementation shortcut. Marco is counting the semicolons from the left, and counting 'Total number of semicolons - expected semicolons after column 3' instead of just counting from the end of the line]
Left([@1:n],Index([@1:n],';',2)) // Find second semicolon, end of second column in line
&'"'&Mid([@1:n],Index([@1:n],';',2)+1,Index([@1:n],';',SubStringCount([@1:n],';')-16)-Index([@1:n],';',2)-1)&'"' // enclose the third column with double quotes
Mid([@1:n],Index([@1:n],';',SubStringCount([@1:n],';')-16)) // add columns 4-20
Once the columns with text is quoted, you can use MSQ style int format specifier to read it in without taking semicolons as separators, separating the line into fields in the data model.
The rest of the script is then mapping the column names to the names used in the file.
If you want to parse your text field located in the 5th column, you need to replace 2 by 4 and 16 by 14 in above expression.
With regard to your issue displaying the character correctly, could you upload a small sample csv file?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
And since Index() does also takes a negative position index, you can simplify the line manipulation to
Left([@1:n],Index([@1:n],';',2))&'"'&Mid([@1:n],Index([@1:n],';',2)+1,Index([@1:n],';',-17)-Index([@1:n],';',2)-1)&'"'&Mid([@1:n],Index([@1:n],';',-17))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
another version that includes an ID field to be able to load files with double rows.
(and some comments, Rob 😉
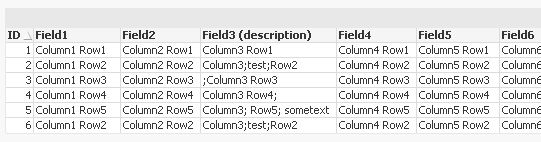
// defining the number of the column that might contain semicolons
LET vColumnWithSemicolon = 3;
LET vColumns = 20;
// load whole lines of csv file without headers and adding double quotes around values of above specified column
// quoted semicolons will not be treated as delimiters. Append Record numbers as additional column to let lines be distinct
table1:
LOAD Left([@1:n],Index([@1:n],';',$(vColumnWithSemicolon)-1))&'"'&Mid([@1:n],Index([@1:n],';',$(vColumnWithSemicolon)-1)+1,Index([@1:n],';',SubStringCount([@1:n],';')+$(vColumnWithSemicolon)-$(vColumns)+1)-Index([@1:n],';',$(vColumnWithSemicolon)-1)-1)&'"'&Mid([@1:n],Index([@1:n],';',SubStringCount([@1:n],';')+$(vColumnWithSemicolon)-$(vColumns)+1))&';'&(RecNo()-1) as line
FROM QlikCommunity_Thread_202456_v2.csv (fix, codepage is 1252)
Where RecNo()>1;
// load separate fields from previously loaded field "line"
// This load creates field names @1 to @n (n being the ID/RecNo field)
table2:
LOAD *
From_Field (table1, line) (txt, codepage is 1252, no labels, delimiter is ';', msq);
// calculate fieldnumber of ID field
LET vIDColumn = $(vColumns)+1;
// create temporary table having columns for old and new field names (header row of csv file + ID field)
tabFieldNames:
CrossTable (oldFieldName,newFieldName)
LOAD 1,*,'ID' as @$(vIDColumn)
FROM QlikCommunity_Thread_202456_v2.csv (txt, codepage is 1252, no labels, delimiter is ';', msq)
Where RecNo()=1;
// create mapping table to translate default field names (@1 to @n) to column headers of csv file
mapFieldNames:
Mapping LOAD oldFieldName, newFieldName
Resident tabFieldNames;
// drop temporary tables
DROP Tables table1, tabFieldNames;
// rename fields using the previously generated mapping table
RENAME Fields using mapFieldNames;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi thank you for the explanation!
I attached a sample file for the encoding issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hallo Sebastian,
utf8 in the from_field load seems to work with umlauts:

// defining the number of the column that might contain semicolons
LET vColumnWithSemicolon = 5;
LET vColumns = 20;
// load whole lines of csv file without headers and adding double quotes around values of above specified column
// quoted semicolons will not be treated as delimiters. Append Record numbers as additional column to let lines be distinct
table1:
LOAD Left([@1:n],Index([@1:n],';',$(vColumnWithSemicolon)-1))&'"'&Mid([@1:n],Index([@1:n],';',$(vColumnWithSemicolon)-1)+1,Index([@1:n],';',SubStringCount([@1:n],';')+$(vColumnWithSemicolon)-$(vColumns)+1)-Index([@1:n],';',$(vColumnWithSemicolon)-1)-1)&'"'&Mid([@1:n],Index([@1:n],';',SubStringCount([@1:n],';')+$(vColumnWithSemicolon)-$(vColumns)+1))&';'&(RecNo()-1) as line
FROM [https://community.qlik.com/servlet/JiveServlet/download/963714-208647/sample.csv] (fix, codepage is 1252)
Where RecNo()>1;
// load separate fields from previously loaded field "line"
// This load creates field names @1 to @n (n being the ID/RecNo field)
table2:
LOAD *
From_Field (table1, line) (txt, utf8, no labels, delimiter is ';', msq);
// calculate fieldnumber of ID field
LET vIDColumn = $(vColumns)+1;
// create temporary table having columns for old and new field names (header row of csv file + ID field)
tabFieldNames:
CrossTable (oldFieldName,newFieldName)
LOAD 1,*,'ID' as @$(vIDColumn)
FROM [https://community.qlik.com/servlet/JiveServlet/download/963714-208647/sample.csv] (txt, codepage is 1252, no labels, delimiter is ';', msq)
Where RecNo()=1;
// create mapping table to translate default field names (@1 to @n) to column headers of csv file
mapFieldNames:
Mapping LOAD oldFieldName, newFieldName
Resident tabFieldNames;
// drop temporary tables
DROP Tables table1, tabFieldNames;
// rename fields using the previously generated mapping table
RENAME Fields using mapFieldNames;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is the challenge created by Peter still open?
Another solution without a field name mapping could be:
// defining the number of the column that might contain semicolons
LET vColumnWithSemicolon = 5;
LET vColumns = 20;
LET vRight = vColumns - vColumnWithSemicolon; //# semicolons counted from the right
LET vLeft = vColumnWithSemicolon-1; //# of semicolons counted from the left
// load whole lines of csv file without headers and adding double quotes around values of above specified column
// quoted semicolons will not be treated as delimiters. Append lines to single LINE
table1:
LOAD
CONCAT(line, chr(10)&chr(13) ,LineNo) as LINE;
LOAD Left([@1:n],Index([@1:n],';',$(vColumnWithSemicolon)-1))&'"'&Mid([@1:n],Index([@1:n],';',$(vColumnWithSemicolon)-1)+1,Index([@1:n],';',-$(vRight))-Index([@1:n],';',$(vLeft))-1) &'"'&Mid([@1:n],Index([@1:n],';',-$(vRight))) as line,
recno() as LineNo
FROM [https://community.qlik.com/servlet/JiveServlet/download/963714-208647/sample.csv] (fix, codepage is 1252)
//Where RecNo()>1
;
// load separate fields from previously loaded field "LINE"
// This load uses embedded field names
table2:
LOAD *
From_Field (table1, LINE) (txt, utf8, embedded labels, delimiter is ';', msq);
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Very nice. an adventurous spirit came up with a trick to treat header lines just like everything else. Why didn't I think of this?
Great improvement, Stefan.