Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: Table transformations
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Table transformations
Hi I have table with one column with structure as is here:
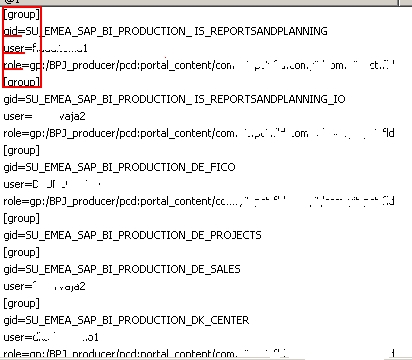
I’d like to apply some transformation, but I don’t know which exactly.
Info between two signs ‘[group]’ is one entry, with 3 columns: gid, user, role (there are exceptions where only gid is available). User and role might have several entries.
My aim is to have at least this table:
gid | user | role |
g1 | u1,u2,u3 | r1,r2,r3 |
g2 | ||
g3 | u1 | r1 |
Please help me with some hints.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
one possible solution:
Input:
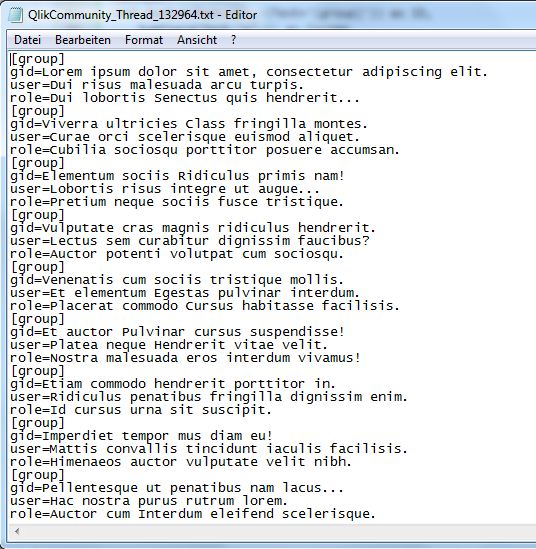
Output:
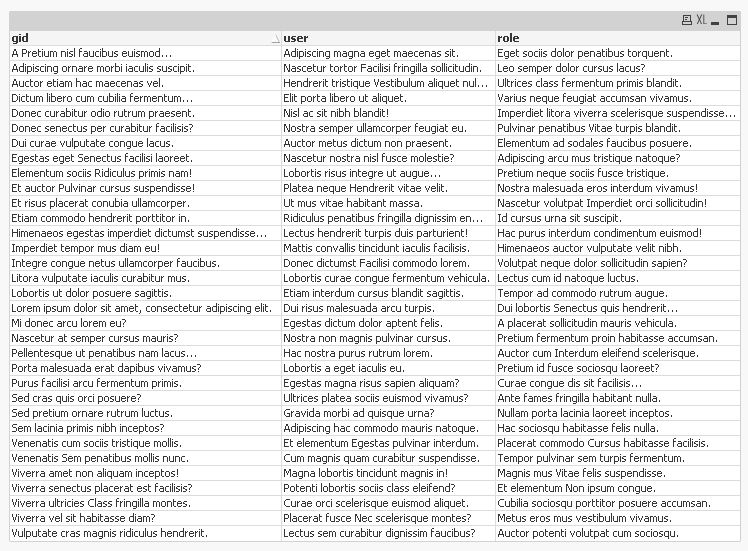
used script:
tabInput:
LOAD NumSum(Peek(ID),-(Text='[group]')) as ID,
SubField(Text,'=',1) as ColNam,
SubField(Text,'=',2) as ColVal;
LOAD [@1:n] as Text
FROM [http://community.qlik.com/servlet/JiveServlet/download/607776-124887/QlikCommunity_Thread_132964.txt] (fix, codepage is 1252, record is 1 lines);
tabOutput:
Generic LOAD *
Resident tabInput
Where ColNam <>'[group]';
DROP Table tabInput;
hope this helps
regards
Marco
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Maybe subfield()?
subfield(s, 'delimiter' [ , index ] )
In its three-parameter version, this script function returns a given substring from a larger string s with delimiter 'delimiter'. index is an optional integer denoting which of the substrings should be returned. If index is omitted when subfield is used in a field expression in a load statement, the subfield function will cause the load statement to automatically generate one full record of input data for each substring that can be found in s.
In its two-parameter version, the subfield function generates one record for each substring that can be taken from a larger string s with the delimiter 'delimiter'. If several subfield functions are used in the same load statement, the Cartesian product of all combinations will be generated.
Examples:
(For three parameters)
subfield(S, ';' ,2) returns 'cde' if S is 'abc;cde;efg'
subfield(S, ';' ,1) returns NULL if S is an empty string
subfield(S, ';' ,1) returns an empty string if S is ';'
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Dusan,
To create a table from that only column you can use something like:
LOAD mid(@1, 1, Index(@1, '=')-1) as field,
mid(@1, Index(@1, '=')+1) as value,
If(mid(@1, 1, Index(@1, '=')-1)='guid', NumSum(1, Peek('Cont')), Peek('Cont')) as Cont
Resident temp where @1<>'[group]';
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is a similar data-structure after the export from windows event-logs to txt-files per "wevtutil". This could be structured per mod(rowno()) - here an example:
... some loops for all logs
... some prepare and cleaning
PrepareData:
Load
EventNr, mod(rowno(), 12) as Mod, /*LineString,*/ LogSource,
if(mod(rowno(), 12) = 0, Peek('Value', rowno() - 1 - 11, 'RawDataResult')) as LogName,
if(mod(rowno(), 12) = 0, Peek('Value', rowno() - 1 - 10, 'RawDataResult')) as Source,
if(mod(rowno(), 12) = 0, date(num(mid(Peek('Value', rowno() - 1 - 9, 'RawDataResult'), 1, 10)) +
num(mid(Peek('Value', rowno() - 1 - 9, 'RawDataResult'), 12, 8)), 'DD.MM.YYYY hh:mm:ss')) as Date,
if(mod(rowno(), 12) = 0, Peek('Value', rowno() - 1 - 8, 'RawDataResult')) as EventID,
if(mod(rowno(), 12) = 0, Peek('Value', rowno() - 1 - 7, 'RawDataResult')) as Task,
if(mod(rowno(), 12) = 0, Peek('Value', rowno() - 1 - 6, 'RawDataResult')) as Level,
if(mod(rowno(), 12) = 0, Peek('Value', rowno() - 1 - 5, 'RawDataResult')) as Opcode,
if(mod(rowno(), 12) = 0, Peek('Value', rowno() - 1 - 4, 'RawDataResult')) as Keyword,
if(mod(rowno(), 12) = 0, Peek('Value', rowno() - 1 - 3, 'RawDataResult')) as User,
if(mod(rowno(), 12) = 0, Peek('Value', rowno() - 1 - 2, 'RawDataResult')) as UserName,
if(mod(rowno(), 12) = 0, peek('Value', rowno() - 1 - 1, 'RawDataResult')) as Computer,
if(mod(rowno(), 12) = 0, Value) as Description
Resident RawDataResult;
SelectDataSystem:
Noconcatenate Load * Resident PrepareData Where Mod = 0;
... some cluster ...
I think you could adapt this approach.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for ideas.
It's maybe not clear from the screenshot, but the text consists of several rows, so the first row is [group], 2nd row 'gid=...', 3rd row is 'user=...' and so on. So subfield() and mid() are not suitable so far.
@Marcus I'll need some time to modify my data structure on your script.
D.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
see attachment
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
one possible solution:
Input:
Output:
used script:
tabInput:
LOAD NumSum(Peek(ID),-(Text='[group]')) as ID,
SubField(Text,'=',1) as ColNam,
SubField(Text,'=',2) as ColVal;
LOAD [@1:n] as Text
FROM [http://community.qlik.com/servlet/JiveServlet/download/607776-124887/QlikCommunity_Thread_132964.txt] (fix, codepage is 1252, record is 1 lines);
tabOutput:
Generic LOAD *
Resident tabInput
Where ColNam <>'[group]';
DROP Table tabInput;
hope this helps
regards
Marco