Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- fields related only to certain value
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
fields related only to certain value
Hi Everybody,
Consider this table:
| Field1 | Field2 |
|---|---|
| A | 1 |
| A | 2 |
| A | 3 |
| A | 4 |
| B | 1 |
| B | 2 |
| B | 3 |
| C | 1 |
| C | 2 |
| D | 1 |
| E | 1 |
| E | 2 |
| E | 3 |
I need to return those rows who have only 1 or 2 in load script. In this case C and D.
Any sugestion?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Maybe using a set expression like
Count( {<Field1 = e({<Field2 = {">2"}>}) >} Field1)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
in load script
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Something like this:
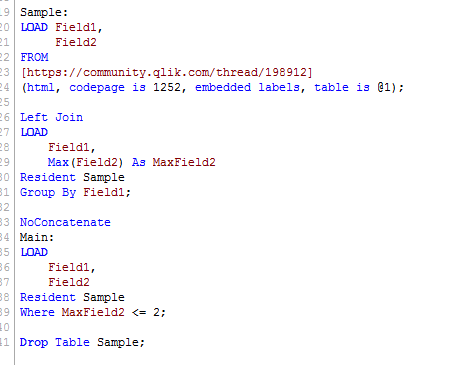
And here is your data model:
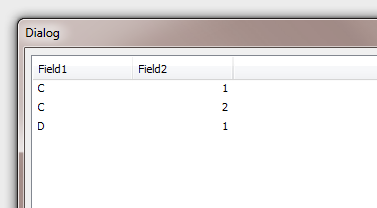
Hope this helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
another one could be
A:
LOAD Field1, Field2
FROM [https://community.qlik.com/thread/198912] (html, codepage is 1252, embedded labels, table is @1);
Right Keep (A)
load Field1 Where match(Filter, '1-2', '1', '2');
load Field1, Concat(DISTINCT Field2, '-', Field2) as Filter
Resident A
Group By Field1;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yet another one could be:
Table:
Load Distinct Field1
FROM Source
Where Field2 = 1 or Field2 = 2;
Fact:
LOAD Field1,
Field2
FROM Source
Where Exists(Field1);
now this is very well a sample but in your case you might have a lot to include and very less to exclude. So you can take an alternative route
Table:
Load Distinct Field1
FROM Source
Where Field2 > 3;
Fact:
LOAD Field1,
Field2
FROM Source
Where not Exists(Field1);
Benefit here is that for large dataset you will be able to avoid aggregation.
HTH
Best,
Sunny