Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: how to ifentify these are synthetic keys ? bef...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
how to ifentify these are synthetic keys ? before developing data model?
how to ifentify these are synthetic keys ? before developing data model?
- Tags:
- new_to_qlikview
- « Previous Replies
-
- 1
- 2
- Next Replies »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I completely agree Steve.
Maybe an additional reason I like polling the sys catalogs for tables and columns is that it helps me track my QlikView "project" (a defined set of tables and fields) across multiple environments.
I had a project that had to traverse DEV, QA, UAT, and PROD environments, except the table structures of the source databases at each environment were not imaged evenly. Not only did the sys tables help me identify the syn keys before creating a base extraction script, but it also showed me which fields were dropping in and out of the data catalog (i.e. present in every stage of the environment progression). That gave some nice heads up of what would happen around the curve, in that "Hey we're able to pull the full data model from DEV right now, but when we are scheduled to go against UAT in 3 weeks, we're going to hit a roadblock because our catalog 2 environments ahead is missing fields."
Then I had another client that wanted to start pulling tables from different environments and mixing and matching them in the final data model. Imagining saying use TABLE1 from UAT, TABLE 2 from DEV, TABLE 3 from PROD, etc... TABLE 1, TABLE 2, and TABLE 3 were present in every environment, but the field structures of each table varied across environments. Tracking this could have been a nightmare, but QlikView saved the day.
Lastly, I don't know if you've ever had that experience where you're certain you had an extraction script all worked out and after initial tests it works fine, but after a success or two it starts failing because explicit fields are missing that you could've sworn were there, or wildcard tag-alongs are causing unintended consequences, and you feel like you're losing your mind. Unless you're privy to dba level communications informing all downstream processes of database structural changes, oftentimes the app designer is forced to react to failures, rather than anticipate and meet updates. In one instance taking snapshots of the catalog and comparing deltas to get the structural changes yielded clarity. Sure enough there was a field that intersected with the QlikView project that was playing "peek-a-boo" and dropping in and out of the database. (i.e. the field would be present in the table during the working hours, when I was using the script wizard to create the extraction script, but kept dropping out of the source table afterhours at some point before the scheduled overnight reload would execute)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I will often pull together a document that looks at the schema of a database or other ODBC source. This will seldom give me any insight into the data models in my QlikView apps - as invariably I will have modified the fields on the way out of the database. At very least things tend to get renamed (to give sensible caps and spaces) but typically also deriving variations of the fields.
What I do find useful for comparing where fields exist in data models between QlikView apps is doing an Export Structure (from the Tables tab in Document Settings) of a number of apps. You can then load these files in for a number of apps into a single QlikView app. This allows you to spot when you have the same field across apps.
I must tidy up the app I use for this and upload it to the Community at some point...
Regarding the field lists changing by virtue of the underlying database changing when a * is used, this will not typically happen to me as I always try and avoid wild cards. Not least for that reason, but also it can mean that far more columns are sent from the database to QlikView for them just to be ignored. The performance hit of sending the fields across the network has already happened at this point.
Without the wildcard the load will fall over with a sensible error message if someone removes a field from the table. If someone adds a field it will not have any impact whatsoever.
I've a number of posts on my blog regarding data modelling in QlikView you may want to take a look at:
http://www.quickintelligence.co.uk/qlikview-blog/
Cheers,
Steve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Great points Steve, I will be checking out (and have been checking out) your blog posts, always appreciate your work.
I guess I found the data catalog approach most useful during QVD layer extraction. If there is a multi-tier approach, it is applied to the "first touch" ETL documents, because naturally the late stage UI layers contain a lot more aliasing.
I was working with a Data Architect from a major financial institution who knew everything about his company's data systems but was brand new to QlikView. During a meeting with this "institution within an institution" I started discussing one of the fields being extracted to QVD from the company's data warehouse where the fieldname had been aliased. When I referenced the field by its aliased name in the meeting, he cut me off and said "We don't even have that field in our database, what are you talking about?" I realized at that point I risked alienating a very important person in the process, because even though aliasing seemed an ordinary enough step to me, it wasn't completely transparent to others unfamiliar with QlikView.
Once I started mirroring the QVD extraction layer with field names identical to the sourcing RDMS systems, the DBA immediately began to trust the process again and resume dialog. In addition, by belaying aliasing until as close to the ui layer as possible, I found that people unfamiliar with QV but still DB technical could discuss field structures of earlier stage QVD and retain understanding of where that source data was originating and what it represented.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Evan,
That is an interesting point about losing the input from the DB guys. I usually find that you don't get a lot from them anyway and bringing the end users on-board by aliasing is better - but I can see it can work the other way also.
When on a greenfield site I try and ensure buy-in and understanding by distributing a spreadsheet with the source field names on and ask someone in the business to fill in the names they want to see in the UI. This also is a good point to identify fields that can be dropped (which will improve performance) and it means there is a document that can be referred to as a data dictionary. Building the load statement can then be done with a CONCATENATE in Excel, bringing the old field name and the new field name together into a statement with an AS and a Comma.
Another point you can pull meta data into QlikView for checking is out of QVDs. You can enumerate around all QVD's in a folder with for each vFile in FileList('$(vFolder)*.qvd') and then if you load from a QVD as an XML file you can read the meta data that includes all field names and definitions. Quite a useful trick. That's another app I must upload at some point...
Glad to hear you read and find useful my blog.
Steve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
if there are more than one common field in the tables, then by seeing that we can say that it will form synthetic keys in the data model
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you want to identify synthetic key for data loading in Qlikview. then carefully check all required Dimension and Fact tables fields if two or more table contains more than one same field name it will end up with synthetic key in Qlikview table viewer (internal table view).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Steve,
Just want to add, the end-users always got their "user friendly" field names, I just moved aliasing to the last step before releasing a user-interface. All ETL layers prior used source DB nomenclature.
Regarding using functions to generate syntax...
Completely with you on using the Excel functions to form scripting syntax for aliasing. I may have some additional ideas on how this can be expanded upon, and also brought back into being performed within QlikView.
I've done a decent amount of exploration for creating programmatic scripting within QlikView, not just for forming QVS syntax, but also with SQL, XML, and DOS. The results have allowed pushbutton generation of complete code routines for all of these languages (and I'm sure more are possible).
For example in our aforementioned scenario, by attaching the data catalog to auto-scripting routines it was possible to create QVS syntax that wrapped the field names from both the QV and native RDMS side (load and preceding) in data typing functions, correlating to their catalog data type definitions.
(why not allow Qlik to intuit the data types and skip explicit data typing functions altogether? Because sometimes in the case of Dual() type fields, it was necessary to control which side of the dual was the pertinent half. Other cases, naked field references were distorting due to potential numeric vs. textual interpretations. i.e. Is '82E2' a text handle for a company division? Or a numeric representation in exponential format? Have you ever had a combined QV field receiving contributions from multiple tables load numeric from the first source, and then get confused because later tables introduce text? vs. versa? Explicit data type functions were closing down a lot of these avenues for data 'misinterpretation')
But if you look at the screenshot, you can see the fully-formed QVS scripts being prepared in the Text object. It takes into account a lot of regularly repeated steps beyond just identify the table name, source, and fields, by also making syntax statements for script tabs, connection strings, comments, STORE, DROP, and DISCONNECT.
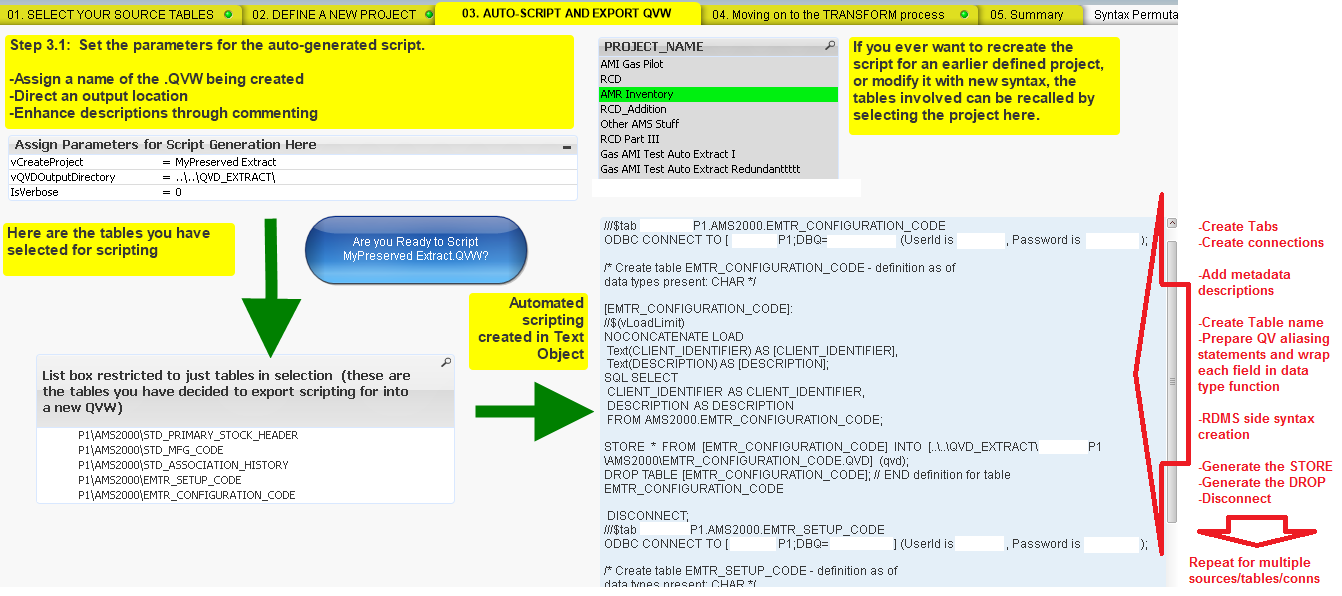
Taking this one step further, I was using a macro to export the formed scripts into brand new .QVW documents. Upon testing the push-button generated ETL .QVW, they were running freshly made without issue and now the creation of all ETL QV scripting within that development environment was completely standardized. And setting the stage for standardization across all projects/environments.
Then lets say the underlying RDMS table structures began to change. Fields dropping in and out, data types shifting, case-sensitive names jumping up and down. To adapt to this, the data catalog was reloaded (even on a schedule), then a project definition identifing the target group of tables was selected, push the 'autogenerate' button again and a modified ETL .QVW up to date with the most current DB definitions was produced, and it did not use wildcard or naked field references in any way.
It was also modified to handle extracting the same table across multiple environments/sources, so if you needed to pull COMPANY_CODES from a DB instance in DEV, QA, and PROD and also from one ORACLE farm and one SQL Server farm, it was able to script an extraction for the same table 6x and make folders/QVD instances that labelled each according to its source so that they wouldn't get confused by being commingled into one giant QVD folder.
Every presentation of this system to clients and Qlik partners has been greeted with lots of enthusiasm, but then during the afterthought, it tends to get buried deeper than Randy Hearst's release of Orson Wells's 'Citizen Kane'  , so I'm not sure when or how an idea of this nature could take form in the general consensus. But for my personal usage, it works great!
, so I'm not sure when or how an idea of this nature could take form in the general consensus. But for my personal usage, it works great!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Evan,
That is a neat bit of coding you have there. I can see it must make your life much easier! The issue I can see is that it is going to pull forward what is in your database as it is in the database. This is great if you are pulling data from a well managed and maintained RDMBS. The scenarios I often find though is databases created by people that don't really understand databases - and in those cases you want to be moving away from that as soon as possible.
I do fully take on board your point about keeping the naming the same to keep your DB professionals on side though.
Rob Wunderlich is getting quite a lot of people picking up and using his QlikView Cookbook library of functions. This falls into a similar area. Promoted right you could well have people interested in using it.
Regards,
Steve
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Steve, I appreciate you taking the time to even read these posts, we kind of got away from the main topic of the thread but being able to share this concept means a lot.
There's one other portion of preserving the underlying structure of the source systems I wanted to mention, it deals with preserving the data "address" information in the folder structure of the extract QVD repository.
When I use this application, it was important to avoid having large amounts of QVDs pile up in a giant folder (and also table names repeat). So the application checks to see if the user is creating an extraction for a new dsn/schema combination from the data catalog. If the combination of dsn/schema's haven't been extracted prior, the application goes out and creates that folder tree in preparation for the landing zone of the QVD output of the newly generated extraction script.
The EXTRACT folder structure was standardized and always followed a specific syntax that mirrored the structure of the RDMS: \{DSN}\{Shema}\{Table}.QVD
That way the load statement for a QVD retains a near identical "address" syntax that the RDMS system uses. Even if I weren't familiar with QlikView, but familiar with databases I should be able to follow the nature of where a QVD is sourcing from, and keeping things in a kind of "apples to apples" comparison.
i.e.
ODBC Connect to MSSQLSRV_QA;
SQL SELECT * FROM [edw].[PRODUCTS];
//has the same navigation attributes as:
LOAD * FROM
[.\MSSQLSRV_QA\edw\PRODUCTS.QVD (qvd);]
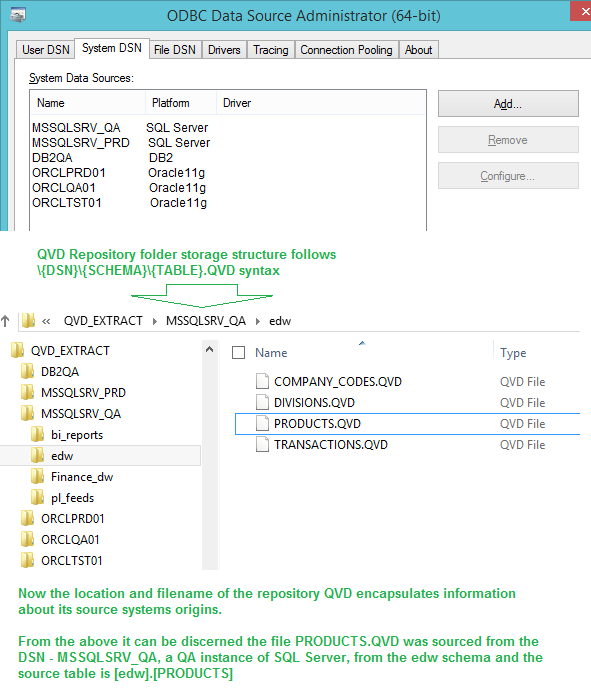
It seems to me this system is generic enough to be compatible with any QlikView installation using ETL layers in conjunction with DSN sources, which has been every project I've ever been on. Maybe we could take this offline and discuss some ideas about presenting this as a proposal like you mentioned, I'd be interested in hearing your thoughts about that. And again, thank you for evaluating the idea. (and thank you manojqlik, sorry about this extra discussion in your thread).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Evan,
This is really very neat. I have used QlikView to persist a database that was being decommissioned by looping through all tables and writing to QVD. All further data was then loaded from those QVDs. Having the folder structure created is an excellent addition to that approach.
I think there is definitely mileage in getting this productionised and moved to Qlik Market.
Something to take to email and out of this thread though.
Cheers,
Steve
- « Previous Replies
-
- 1
- 2
- Next Replies »