Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Re: island Calendar and expressions
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
island Calendar and expressions
Hi,
I have this model
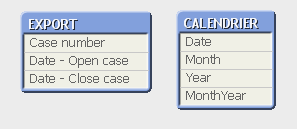
and I want a table per MonthYear with :
- the number of new cases : count({$<[Date - Open case]={">=$(=min(Date))<=$(=max(Date))"}>} distinct [Case number])
- the number of close cases : count({$<[Date - Close case]={">=$(=min(Date))<=$(=max(Date))"}>} distinct [Case number])
- the number of still open cases : count({$<[Date - Open case]={"<=$(=max(Date))"}, [Date - Close case]={">=$(=max(Date))"}>} distinct [Case number])
I don't understand my mistake because these expressions doesn't work as I which. I would like the result per month and I have the total of the year each month
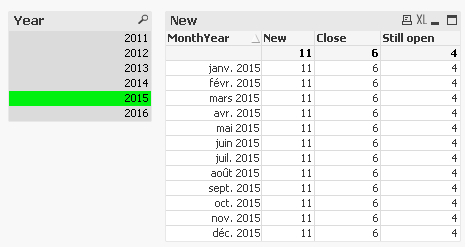
Thanks for your help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The reason for this are the adhoc-variables - $(=min(Date)) - within the set analysis which won't be evaluated on row-level else global for the whole chart before calculating the chart and then applied for each row. I'm not sure if your approach with using a loosen table to define your expression-filters will be successful. I suggest to consider to connect your tables with a IntervalMatch.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Anthony!
In your model there's no relation beetween the tables that's why you alway see the entire year data. You need to create a date field in the "Export" table with the same name of a field in the "Calendrier" table just to create the dependencies of the data.
Best regards,
Marcello
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your help.
I would like to avoid using intervalmatch because it creates too many millions of records and the size of the application will grow to fast.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You are right that such resulting link-table could be quite big and slow down the whole application. But you could try to join the table with another table or maybe to precalculate it in any way.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Anyboby has une better solution that the intervalmatch?
The response time for my expressions is too slow with the intervalmatch. Is there any solution via a set analysis or other?
Thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try it with if-loops instead of set analysis, something like:
count(distinct if([Date - Open case] >= min(Date) and [Date - Open case] <=max(Date), [Case number]))
or maybe more performant:
if([Date - Open case] >= min(Date) and [Date - Open case] <=max(Date), count(distinct [Case number]))
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have always found IntervalMatch() to perform well, even with 10+ million fact tables.
One thought though, are your dates pure dates and not timestamps formatted as dates but stored with their decimal time bits? If so that could well cause performance issues with interval match.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, it's a good advice.
I didn't think about that. Thanks.