Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView App Dev
- :
- Do variable relations affect document size?
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do variable relations affect document size?
Hello everyone,
I've been for a while into optimize my model. After reading ByteSizes from Values in QlikView optimized the size of my variables but i see that the size of my document has not decreased acordingly. Tot test it better I loaded al the data on a empty QV, generated a .mem file. As a result, my QV shout size 26,543 KB but the real size is 99,775 KB
1- I wonder where this 73,232 KB come from because is a lot of space and it should be this amount of space given the change of variable size from on the optimitzation.
2- Doing the same comparasion with the old QV the result is 163,734 - 220,701 = - 569,671 KB. So the document should be bigger than it really is!. I think that this case is easyer to understand than the other due to the compression but it is stillsurprising me.
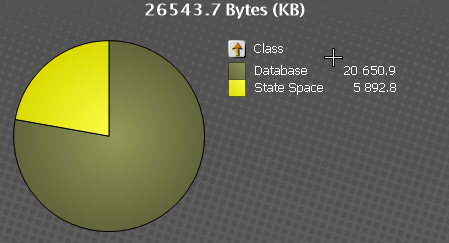
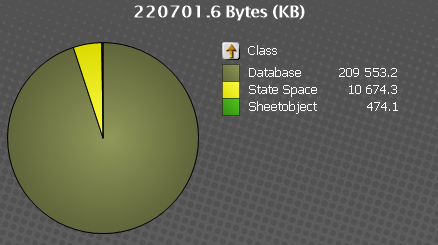

Also I have read in the community to download the governance dashboard in order to ber more sure about where this space can be from, but I am not able find it. I tried : http://eu-a.demo.qlik.com/download/?utm_source=RWPPortal&utm_medium=promo1&utm_campaign=DownloadQlik and I am not able to see wher to download it. Also I read.
Thank You
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The size of QVW, by default is that of the QVW highly compressed. You can change this setting in the QlikView Desktop menu Settings > Document Properties > General > Save Format > Compression. In memory the model is expanded and it always uses much more, both in the Desktop (qv.exe) and in the server (qvs.exe).
Rule of thumb says that, by default and in general, and always taken with a grain of salt, the ratio of compressed (QVW size in disk) versus uncompressed (memory footprint for 1 user) could be 1:4, which matches almost perfectly with your numbers: the disk uses 26MB in disk but 99MB in memory.
Also, if you are comparing QV11 generated apps with QV12 generated apps, the difference should be noticeable, QV11 using considerably less disk than QV12 apps. This is known and expected.
On another side, bigger documents are more likely to have less unique values, so the compression will be higher. For example, if you are loading 100 customers in the app, each of them with 1 transaction, you will store 100 distinct values for the customer details: name, id, address, etc. But if every customer has instead 1000 transactions, you are still keeping only 100 distinct values for all fields related to the customer. A lot of those values are repeated and it will add up to the savings in space (also in memory footprint!).
As you can read in the post by Marcus and all the linked documentation, this is just that: a rule of thumb. Any non integer numeric value will use more space, generally speaking, than strings. Also, more columns with numeric non integer values, like amounts in transactions with decimals, with use more space than integer only values (IDs, dates, etc.).
In addition, these values are less likely to be repeated, depending on the analysis. A retail store with items and prices will have more repeated values -therefore, resulting in a more "compressed" file and less memory usage- than a dashboard with financial ledger records, where the numbers vary a lot.
In reality, the compression is the same, but as the occurrence of repeated values increases, so does the savings in space.
As for the Governance Dashboard, contact Qlik Qoncierge and ask them to let you access the corresponding download area.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello, mbaeyens thank you for your response.
I already knew about the compresion and I tested the file sizes and what I get coincides with what you are telling me: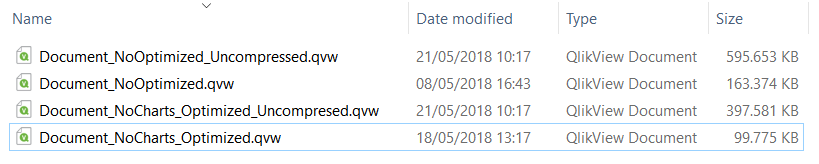
Right, thank you for the advises. Actually is what I did in order to get the "optimized" document Reduce the number of unique values (rounding decimal fields and split timestamps into two fields: Day, Hour) and reformat to numeric fields those that where numeric and ocuppy more than 8 bit per symbol (in some case even 24).
As far as I know, the uncompressed file size is the same as the ram one in order to optimise load time. Thus, I don't get the key about which memory is in the .mem files because it's neither the RAM size: does not coincide with the uncompressed document size 595MB not 220MB, for the unoptimized, and 397MB not 20 MB, for the optimized. Nor the compressed file size as we saw before.
As for the Governance, I contacted support and downloaded it now I am trying tot test it on my models.