Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics & AI
- :
- Products & Topics
- :
- Visualization and Usability
- :
- Set analysis for embedded SQL query
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Set analysis for embedded SQL query
Hi All,
Need help with set analysis for embedded SQL query. see below sample table and the queries..
Thanks for your help!
Table Name: ABCD
| Conversation_id | Timestamp | Text |
| 1 | 2:35 | Hi.asdf |
| 1 | 3:45 | xyz |
| 1 | 4:00 | Thanks.wer |
| 2 | 4:15 | Hi.wert |
| 2 | 4:20 | No |
| 2 | 4:21 | Bye.111 |
| 3 | 4:30 | Hi.rytu |
| 3 | 4:34 | Bye.111 |
#1 - How many records with Text "Hi…"?
SQL query : select count(Conversation_id) from ABCD where Text like 'Hi.%'
Set analysis expression : Count( {$<Text= {"Hi.*"}>} Conversation_id)
Result : 3
#2 - How many records with Text "Bye..."?
SQL query : select count(Conversation_id) from ABCD where Text like 'Bye.%'
Set analysis expression : Count( {$<Text= {"Bye.*"}>} Conversation_id)
Result : 2
#3 - How many records with Text "Hi…" and then followed by text "Thanks…" for a given conversation_id??
SQL query : select count (Distinct w1.Conversation_id) from ABCD w1 where Text like 'Hi.%' and w1.Conversation_id in (select w2.Conversation_id from ABCD w2 where w2.Text like 'Thanks.%' and w2.Timestamp > w1.Timestamp)
Set analysis expression : NEED HELP
Expected Result : 1
-Bas
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
=count({<Conversation_id = p({<Text = {"Hi.*"}>}) * p({<Text = {"Bye.*"}>}) >} distinct Conversation_id)
Regards,
Joshua.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the response.
With the above set analysis, I am getting result as 2. But from the sample data, we should be expecting the result as 1. please see attached screenshot..
Also, with the real data i could see the value doubled with the same formula just like the sample result. what would be the reason?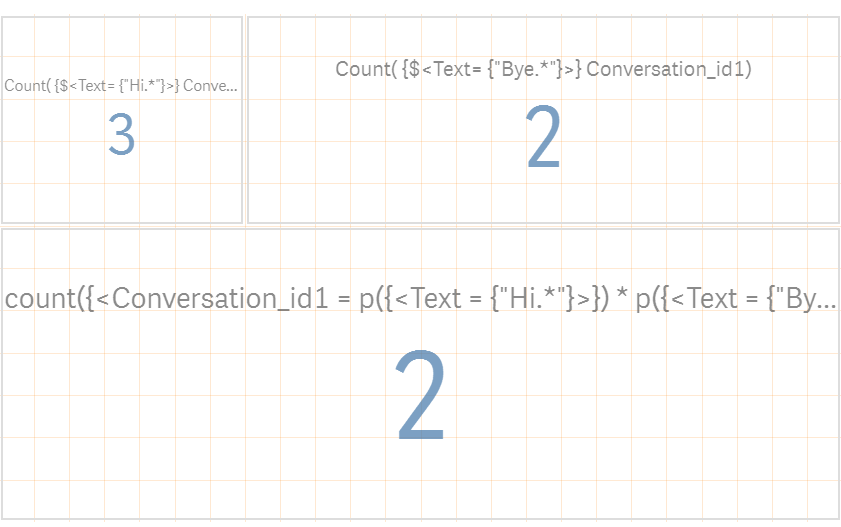
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
appreciate if someone can look into this and provide some advise.
thanks
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
PFA
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try Like this,
ABCD:
LOAD * Inline [
Conversation_id, Timestamp, Text
1, 2:35, Hi.asdf
1, 3:45, xyz
1, 4:00, Thanks.wer
2, 4:15, Hi.wert
2, 4:20, No
2, 4:21, Bye.111
3, 4:30, Hi.rytu
3, 4:34, Bye.111
];
Join
LOAD Conversation_id,Timestamp as Timestamp1;
LOAD * Inline [
Conversation_id, Timestamp, Text
1, 2:35, Hi.asdf
1, 3:45, xyz
1, 4:00, Thanks.wer
2, 4:15, Hi.wert
2, 4:20, No
2, 4:21, Bye.111
3, 4:30, Hi.rytu
3, 4:34, Bye.111
];
Final:
LOAD Conversation_id,Timestamp,Text,
if(Text like 'Thanks.*' and Timestamp>Timestamp1,1,0) as ThanksFlag,
if(Text like 'Hi.*',1,0) as HiFlag
Resident ABCD;
DROP Table ABCD;
Expression like this:
Count(Distinct {<HiFlag={1},ThanksFlag={1}>}Conversation_id)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your response.. the only thing missing is the timestamp condition in the query. Could you help me on this as well?
select count (Distinct w1.Conversation_id) from ABCD w1 where Text like 'Hi.%' and w1.Conversation_id in (select w2.Conversation_id from ABCD w2 where w2.Text like 'Thanks.%' and w2.Timestamp > w1.Timestamp)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
this works  thank you.
thank you.