Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- Optimize UI Performance with Flags and Set Analysi...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Optimize UI Performance with Flags and Set Analysis
In my prior work as a developer and in talking with my Qlik peers there is agreement that creating binary flags in the script (to assist in identifying key segments) is best practice. Anytime you can pre-process data in the script, the UI will perform faster and have less work to do.
Less widely understood is what to do in the UI once the flags have been created. How should these flags be used in expressions? Which approach yields the best performance? One valid typical approach uses set analysis in the following manner to sum Sales where the flag is true:
=sum({$<ScriptFlag = {1}>} SalesAmount)
However, this approach still requires the UI to conditionally evaluate a true/false comparison. From a performance standpoint (important with big data) there is an alternate approach I recommend - special thanks to Kris Balow (@KrisBalow) from Grange Insurance for suggesting this:
When leveraging binary flags (0,1) from the script, simple multiplication of the (flag * metric) performs much faster in the application UI. In my testing, both methods appear to return valid results.
This concept may not work with all aggregate functions, but sum, avg, and count are compatible. Just think about the math before you do it. It’s faster than set analysis because there is no conditional evaluation involved. It’s a simple straight calculation across all records.
Recently I saw a 70% improvement in response time in a customer application by making this simple shift. Using set analysis the response time between clicks was 4-6 seconds. Using straight multiplication it dropped to 1-2 seconds. In this case, a pretty big deal for the users who were making 500+ selections a day. As always, performance lifts will depend on the application.
=sum(ScriptFlag * SalesAmount) – performs much faster
Questions:
- What performance lift do you get?
- What limitations do you see with this approach?
Regards,
Kyle
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have just like you also made some test and compared the different cases. I will write a blog post about the results, but I can already now say the following:
There is some overhead with Set Analysis that multiplication doesn't have, and as a consequence multiplication outperforms Set Analysis in small data sets (~1M rec). But if the data set becomes larger, Set Analysis outperforms multiplication.
Hence, in the cases where you need performance, Set Analysis is the best choice.
HIC
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Kyle,
This is a great "Pub question". It's been argued over many beers for many years. On the question of multiplication vs set analysis, I would say that one does not always perform better than the other. There was a great thread here in the long gone wiki (referenced in this thread Performance: Set Analysis vs. IF vs. Multiplication) where case studies proved both points.
Oleg Troyansky, who is my performance goto person, has done studies that choose Set Analysis as the fastest approach. Although I know I've been able to create an example where multiplication is faster, I haven't been able to produce a current example for him.
In your post you say that Set Analysis requires a conditional true/false evaluation. Set Analysis uses the selection engine and does not make conditional row by row tests.
Update: I just reran John's benchmark from the thread, and Multiplication performed much better than Set Analysis. This is contrary to the results he published in 2009. Then I moved the flag field from the fact table to a separate table -- which would be a common if using a master calendar -- and Set Analysis outperformed Multiplication. That makes sense as the multiplication is no longer a single row operation.
Kyle, in the case you cited above, is your flag on the fact table? ie same table as SalesAmount?
-Rob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is very insightful. In both cases (multiplication and set analysis) are flags being used?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jacob - yes, in both cases flags are being used.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Rob - you make a great point: "One does not always outperform the other". While I've not yet encountered that, your recent test highlights this. This is understandable given how UI layout, expression syntax and data model design all contribute to overall performance. As outlined here Qlik provides testing tools such as the Memory Statistics file or QlikOptimizer.qvw to see what is the best approach.
Example I cited, where multiplication outperformed:
- data model design was multiple fact tables joined through a link table
- master calendar joined to link table (flags here)
- 15 expressions updating with each click: (i.e. uses multiple time period flags paired and multiple facts)
- Variables used in expressions allowing users to select which time period flag is used in the expression.
- Volume: ~10 million records
Kyle
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Rob Wunderlich pointed me to this thread as I was also running some tests on this subject. My findings were that overall multiplication seem to outperform (or perform at least as well as) SA in nearly every scenario:
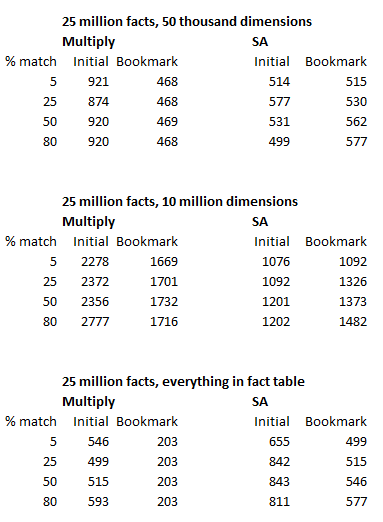
- Metrics in fact table (25 million records), flags in small dimension table (50k records): multiplication around 10% - 20% faster
- Metric in fact table (25 million records), flags in large dimension table (10 million records): SA 25% - 50% faster
- Metrics and flags both in a single fact table (25 million records): multiplication around 60% faster
While in the large dimension table SA outperforms multiplication considerably, this is probably not a scenario that you encounter every day. Overall, my tests seem to indicate that multiplication is a better 'default' option.
What's interesting to note (and this makes sense) is that multiplication has nearly identical performance irrespective of the number of matching flags (as it process all flags in the current selection state, whether they match or not). I did tests with flags matching on 5%, 25%, 50% and 80% of the records and multiplication performed consistently.
For Set Analysis, a higher number of matches led to lower performance. Between 5 and 80% matches there was a 12% decrease in performance for the fact table/small dimension table scenario, and even a 35% decrease in performance for the fact table/large dimension table (but still faster than multiplication).
My full results are shown below. QlikView caching was disabled and for each test QlikView was closed and reopened. The "initial" column shows the calculation time right after opening the document, the "bookmark" column shows the calculation time after selecting a bookmark with a single filter value.
Note that multiplication does seem to perform worse when first opening the file, but that looks like a minor drawback to me, as it only happens once, whereas selections are made constantly. Also note that my test methodology might be flawed/skewed in some way, I tried to control for every variable but might've overlooked something (and if you see anything, do not hesitate to point it out). I will probably retest this on an actual client application to see if real-world result match my "lab" results.
/CC Henric Cronström, based on general recommendations, I was expecting SA to outperform multiplication. Perhaps you can shed some light on how QlikView handles these things "under the hood"? Or, has there been some additional optimization in newer version of QV? (like with Count(DISTINCT))
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I suspect that the main difference is where the flag is - in the fact table or in the dimension table.
Further, there are four ways to use a flag:
- Sum(If(Flag='True', Amount)) // String comparison
- Sum(If(Flag, Amount)) // Boolean condition
- Sum(Flag * Amount) // Multiplication
- Sum({$<Flag={1}>} Amount) // Set Analysis
I suspect that the string comparison is the really expensive one, and the others are (roughly) comparable.
I will look into it and come back.
HIC
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Barry,
really interesting findings so far. What also should be considered in a comparison is the workload on the cores and the probabily of cache reuse. If the overall workload is lower on one approach it would help in a multiuser environment to keep free ressources for other tasks and I would prefer it even with an additional processing time.
Also, I would guess that the cache reuse probability of set analysis is higher since very often the same "filter" is used in different expressions and it could just grab the same set of data. But this should be measured out somehow or someone from the labs could know..
- Ralf
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Provocative comment Ralf.
" I would guess that the cache reuse probability of set analysis is higher since very often the same "filter" is used in different expressions and it could just grab the same set of data."
My read of Henric Cronström post http://community.qlik.com/blogs/qlikviewdesignblog/2014/04/14/the-qlikview-cache was that cache stores the results of data + expression. If the data set is itself a separate cache element that would radically change my understanding of the cache.
-Rob
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ralf is right. A Set Analysis calculation is a two-step process:
- The Set is calculated (like a selection) and cached, and
- The chart aggregation is calculated and cached
Hence, if the same Set is used in several charts, it will indeed make use of the cache efficiently.
HIC
- « Previous Replies
-
- 1
- 2
- Next Replies »