Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- All Forums
- :
- QlikView
- :
- understanding the 'num#' function
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
understanding the 'num#' function
Hi Guys,
I'm still a qlikview newbie, so please forgive me for my questions.
I don't know how the num# function works.
I have 2 fields which qlikview interpetes as text: Population and "% of world population"
China has a population of 1,339,724,852. How can I use the num# function to translate it to numbers. Does eachnumber represents a
'#' so I my case it would be #.###.###.###. I've tried that but that didn't work. 
As far for % world population most countries have a population of 0,000000x%. '#,######%' that unfortunatelly not correct.
Can someone please explain how to use the num# function. I've read the Qlikview refference but didn't understand it.
What the difference between num and num#?
I don't want to change the SET settings, because I want to learn how the num# function works.
Please Help!!
Isam
- Tags:
- new_to_qlikview
- « Previous Replies
-
- 1
- 2
- Next Replies »
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi iSam,
as we say, there are no stupid questions, only stupid answers 😉
The second parameter '#.' is not the millions separator (as Miguel aready said), it's the format code. There are no special millions, billions etc. separators, the thousands separator is just reused for that.
I slightly disagree with Miguel with respect to the format code, I think '#.#' (or even '#') does make sense, because I personally want to read in the value as close to the original as possible (in most cases). So I want to get any number of digits before and any number of digits after the decimal point which come in from original source. Besides that, it seems that '#' and '#,##0.00' format codes don't make much of a difference when parsing numbers in, see attached and below.
I want to format the number only for the output, maybe like num(numPopulation,'#,##0.00'), though I don't think decimal places in a population number are useful.
So for the parsing in, I believe I just have to ensure that my separators are correct (if and only if I have a standard number format, with thousands (if separated) grouped in groups of three, any number of decimal places. If there is a special format (numbers with special separators, mixed with characters or grouped in groups different from three, I absolutely need to specify the exact input format).
For the output I then might use any format code to specify the number of decimal places, add currency symbols etc.
As example, I reused your sample and read it in binary, then applied some different format codes on the Population field:
Binary delete.qvw;
SET ThousandSep='.';
SET DecimalSep=',';
SET MoneyThousandSep='.';
SET MoneyDecimalSep=',';
SET MoneyFormat='€ #.##0,00;€ -#.##0,00';
SET TimeFormat='h:mm:ss';
SET DateFormat='D-M-YYYY';
SET TimestampFormat='D-M-YYYY h:mm:ss[.fff]';
SET MonthNames='jan;feb;mrt;apr;mei;jun;jul;aug;sep;okt;nov;dec';
SET DayNames='ma;di;wo;do;vr;za;zo';
Nums:
Load
CountryName,
num#(Population, '#','.',',') as numPopulation1, // my suggestion (originally '#.')
num#(Population, '#,##0.00','.',',') as numPopulation2, // Miguels suggestion
num#(Population, '#,#','.',',') as numPopulation3 // example for different format code, see below
resident PopulationData;
NumTest:
LOAD
num#('123,433.123', '#' ,'.',',') as numTest1,
num#('123,433.123','#,###.00','.',',') as numTest2,
num#('123,433.123','#.#','.',',') as numTest3
Autogenerate 1;
It seems to me, that numPopulation1 and numPopulation2 result in the same - if the input has a standard (see above, I'm talking about the thousands grouping now) format, the number is correctly read in.
Also, using a specification for the decimal places like '.00' for exact two places seems to have no effect when reading in the numbers, see also the NumTest table for example.
You will notice in attached app, that there are still some strings left unparsed to numbers, like the population of Cook Islands, which reads 24,6. Both the format codes of numTest1 and numTest2 will not parse them correctly, because the thousands grouping is non standard (3 digits after the ',' are expected).
I added a format code in numPopulation3 to parse this value in, as example for a special format. But please note that this string value 24,6 is probably due to the fact that (this is what I assume) the original value in your database is probably 24,600 (read as 24 thousand 600) and your original load with your decimal separator set to ',' will read this in as 24,6 (read as 24 point 6) and removed the trailing zeros.
So you must take care getting the number parsing correct at the moment you read the numbers in from your original source (using num# and appropriate format code and separators), after that, you will be in trouble to get all strings correctly reparsed.
Hope this helps,
Stefan
edit: some typos removed
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi there: take a look at this link for some pointers to understand num & num#
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks! But that doens't explain how to use the num#. I'm more interested in translating numbers using the num# function.
So for example:
1.000.000 OR
0,5% OR
0,0000004
does each number represent a '#'?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Isam,
To make it simpler: "#" is used in a format when you want to specify a possible digit while "0" is used to force a digit, even when there is no need, when it will be replaced by a zero. As an example:
Num#('0,002', '0,00000')
Will show "0,00200" (two trailing zeroes, even when the evaluation doesn't return such figures). But instead
Num#('10,2', '#.##0,###')
Will show "10,2" because there are no hundreds or thousands, and only one decimal position. When you use an expression within as the first parameter, instead of fixed text or numbers as in the examples above, this is the way to force QlikView to represent one decimal, two, none, only if they exist but not always...
Hope that makes sense.
BI Consultant
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
aboumejjane,
please note that num# function also takes up to 4 parameter, paramter 3 defines the decimal separator and parameter 4 the thousand separator.
If I have seen correctly, your separators set in the script via SET does not match the separators used in the input file, that's why you get many values read in as string.
So above chinese population should probably read in as
num#('1,339,724,852', '#.#', '.', ',' )
And then you could use num function to format the numerical value anyway you want.
Hope this helps,
Stefan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Stefan,
My expression is now: num#(population, ‘#.#', '.', ',' ). If I understand the expression correctly ‘#.#’ stand for the million separator and the ‘.’ For the thousand separator and the ‘,’ for decimal. I just don’t understand why there has to be a dot between # (#.#)? Does that represent the separator?
I’m sorry for these ‘stupid’ questions. Just trying to understand how the scripting works, as I’m not (yet) a programmer.
Thanks in Advance!
iSam
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Isam,
num#(population, '#.#', '.', ',' )
- population is the value you want to interpret as numeric (read further about representation and interpretation among many others)
- '#.#' is the format you want values in population be represented. This format in particular makes little sense, although it will work as any number of integers and any number of decimals
- '.' is the decimal separator
- ',' is the thousand separator
So according to you expression, this one should return as expected
Num#(population, '#,##0.00', '.', ',')
Which reads "interpret values in population with a comma as thousand separator, period as decimal separator, and return the value always with two decimal digits and only two, and if the number is integer and has no decimals, set it to, for example 1,250.00 -always two decimal positions even if zero"
Hope that helps.
BI Consultant
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi iSam,
as we say, there are no stupid questions, only stupid answers 😉
The second parameter '#.' is not the millions separator (as Miguel aready said), it's the format code. There are no special millions, billions etc. separators, the thousands separator is just reused for that.
I slightly disagree with Miguel with respect to the format code, I think '#.#' (or even '#') does make sense, because I personally want to read in the value as close to the original as possible (in most cases). So I want to get any number of digits before and any number of digits after the decimal point which come in from original source. Besides that, it seems that '#' and '#,##0.00' format codes don't make much of a difference when parsing numbers in, see attached and below.
I want to format the number only for the output, maybe like num(numPopulation,'#,##0.00'), though I don't think decimal places in a population number are useful.
So for the parsing in, I believe I just have to ensure that my separators are correct (if and only if I have a standard number format, with thousands (if separated) grouped in groups of three, any number of decimal places. If there is a special format (numbers with special separators, mixed with characters or grouped in groups different from three, I absolutely need to specify the exact input format).
For the output I then might use any format code to specify the number of decimal places, add currency symbols etc.
As example, I reused your sample and read it in binary, then applied some different format codes on the Population field:
Binary delete.qvw;
SET ThousandSep='.';
SET DecimalSep=',';
SET MoneyThousandSep='.';
SET MoneyDecimalSep=',';
SET MoneyFormat='€ #.##0,00;€ -#.##0,00';
SET TimeFormat='h:mm:ss';
SET DateFormat='D-M-YYYY';
SET TimestampFormat='D-M-YYYY h:mm:ss[.fff]';
SET MonthNames='jan;feb;mrt;apr;mei;jun;jul;aug;sep;okt;nov;dec';
SET DayNames='ma;di;wo;do;vr;za;zo';
Nums:
Load
CountryName,
num#(Population, '#','.',',') as numPopulation1, // my suggestion (originally '#.')
num#(Population, '#,##0.00','.',',') as numPopulation2, // Miguels suggestion
num#(Population, '#,#','.',',') as numPopulation3 // example for different format code, see below
resident PopulationData;
NumTest:
LOAD
num#('123,433.123', '#' ,'.',',') as numTest1,
num#('123,433.123','#,###.00','.',',') as numTest2,
num#('123,433.123','#.#','.',',') as numTest3
Autogenerate 1;
It seems to me, that numPopulation1 and numPopulation2 result in the same - if the input has a standard (see above, I'm talking about the thousands grouping now) format, the number is correctly read in.
Also, using a specification for the decimal places like '.00' for exact two places seems to have no effect when reading in the numbers, see also the NumTest table for example.
You will notice in attached app, that there are still some strings left unparsed to numbers, like the population of Cook Islands, which reads 24,6. Both the format codes of numTest1 and numTest2 will not parse them correctly, because the thousands grouping is non standard (3 digits after the ',' are expected).
I added a format code in numPopulation3 to parse this value in, as example for a special format. But please note that this string value 24,6 is probably due to the fact that (this is what I assume) the original value in your database is probably 24,600 (read as 24 thousand 600) and your original load with your decimal separator set to ',' will read this in as 24,6 (read as 24 point 6) and removed the trailing zeros.
So you must take care getting the number parsing correct at the moment you read the numbers in from your original source (using num# and appropriate format code and separators), after that, you will be in trouble to get all strings correctly reparsed.
Hope this helps,
Stefan
edit: some typos removed
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Stefan,
Thank you so much for your effort to explain the num# function :D. It’s more clear now. Yeeeey!!!
And thank you to Miguel for your explanation!!! 
Cheers!!
iSam
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm confused why this function supports a format string (i.e. the second argument to NUM(...) and NUM#(...))
-- since that format string can specify its thousands separator
-- then why do they accept a thousands separator string -- the third argument to NUM(...) and NUM#(...)
It seems redundant?
Now, it does allow you to do like swuehl has done
That is, don't mention the thousand separator in the format string, so you can mention it only in the thousands-separator string:
NUM#(Population, '#','.',',') as numPopulation1
However, what happens if you do both -- and they're inconsistent?
And how does this relate to the "Number" tab?
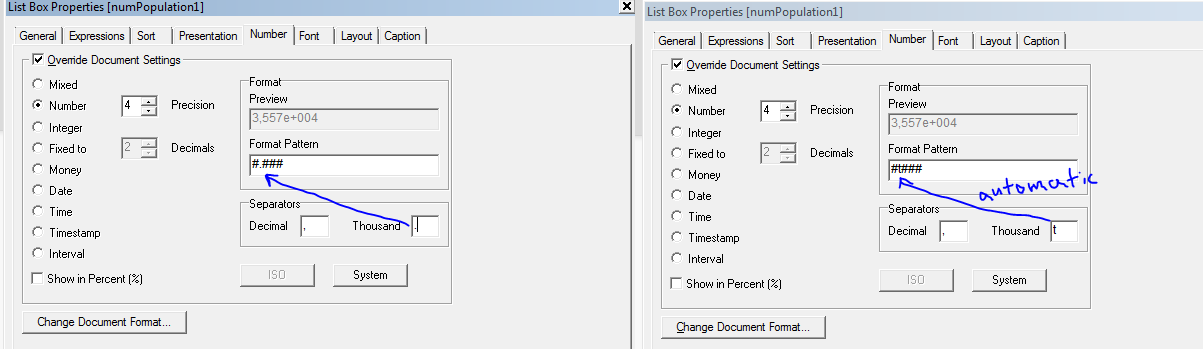
- « Previous Replies
-
- 1
- 2
- Next Replies »