Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics & AI
- :
- Products & Topics
- :
- App Development
- :
- Re: How to go from several rows per ID to one row ...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How to go from several rows per ID to one row per ID with several columns in load script?
Hi there,
In Qlik Sense load script, how can I convert the data in the rows and columns in the Excel-file into the rows and columns that I want? Please see inserted picture (also attached).
The data below is just an example. The actual data set is much bigger so I need an automated way of handling the conversion.

BR Kim
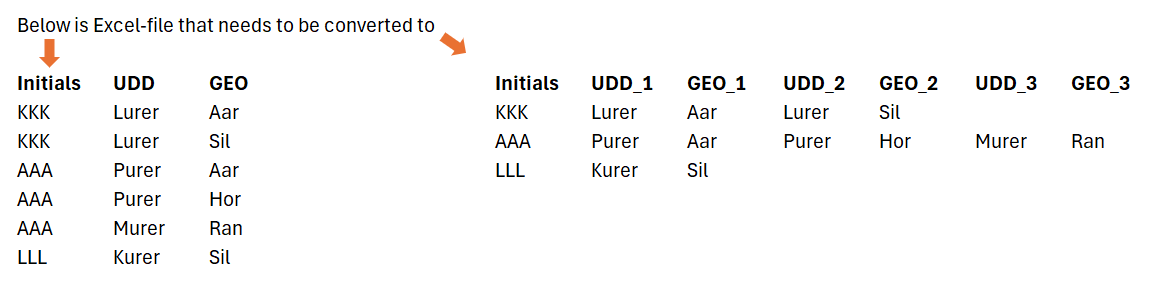{kind=link}
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @blipblopdk
It is probably not the fanciest code, but it seems to work. Let me know if it works for you:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @blipblopdk
It is probably not the fanciest code, but it seems to work. Let me know if it works for you:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Daniel,
Thank you SO very much. It works flawlessly in my end. I have more columns in my original data set, but I think that I can probably work out from your code how to make that work, also.
BR Kim
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can other way using by Generic Load
TempLoad1:
LOAD * INLINE [
Initials, UDD, GEO
KKK, Lurer, Aar
KKK, Lurer, Sil
AAA, Purer, Aar
AAA, Purer, Hor
AAA, Murer, Ran
LLL, Kurer, Sil
];
TempLoad:
Load
Initials,
UDD,
GEO,
If(Initials = Peek('Initials'), Peek('RowCounter') + 1, 1) AS RowCounter
ORDER BY Initials;
Drop table Tempload1;
StackTable:
LOAD
Initials,
RowCounter & '_UDD' AS FieldName,
UDD AS FieldValue
RESIDENT TempLoad;
CONCATENATE (StackTable)
LOAD
Initials,
RowCounter & '_GEO' AS FieldName,
GEO AS FieldValue
RESIDENT TempLoad;
DROP TABLE TempLoad;
FinalTable:
Generic LOAD
Initials,
FieldName,
FieldValue
RESIDENT StackTable;
DROP TABLE StackTable;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can handle this by using a pivot-style transformation in the Qlik Sense load script with a Generic Load. It restructures repeated rows into separate fields automatically. I used a similar approach recently while organizing some test data in Y888, and it worked smoothly here too.