Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Analytics & AI
- :
- Products & Topics
- :
- App Development
- :
- Re: Link Table for Dimension Tables Only
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Link Table for Dimension Tables Only
I have many dimension tables - for purposes of this discussion, we'll whittle it down to 3. This is an iterative load, so it's important that I inject a timestamp to each table load as there are no dates in the source data.
A) All tables are dimension tables and have a primary key. there are no FACT tables.
B) Each table links to a primary key in one or more other tables, but there are no circular references.
Table1:
Load
FirstID
Somedata1
Somedata11
now() as timestamp
From: source1.qvd
Table2:
Load
SecondID
Somedata2
Somedata22
FirstID
ThirdID
now() as timestamp
From: source2.qvd
Table3:
Load
ThirdID
Somedata3
Somedata33
FirstID
now() as timestamp
From: source3.qvd
As you see, the tables link together by different IDs, so they each share at least 1 common field + the timestamp field. Some have only 1+timestamp, others can have 4 or 5 fields + timestamp.
Concatenating probably isn't the best choice here as the data needs to be separated as it's quite disparate. I assume a Link Table would be in order, though I'm not quite sure how to get that done.
I get the concept of generating a composite key, but as there are many tables, and the only 'common' field that ALL of them share is the timestamp. outside of that, they share a variety of different combinations. I started by renaming each timestamp field, but that defeats the purpose and would be quite silly creating visualizations (the intent is to create trending analysis views).
By letting the Synthetic Key Table happen, it's quite convoluted with many $Syn keys.
Thoughts?
Thanks in advance!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your example is quite generic so that's not possible to give a concrete advice but I suggest strongly to avoid the synthetic keys and to do something like this:
Table1:
Load
FirstID
Somedata1
Somedata11
From: source1.qvd
Table2:
Load
SecondID
Somedata2
Somedata22
FirstID
From: source2.qvd
Table3:
Load
ThirdID
Somedata3
Somedata33
FirstID
From: source3.qvd
Depending on the relationship from the dimensions might be the need to merge some per concatenating/joing/mapping and also the use of composite keys between some of them could be necessary. Further I don't see any use of the timestamp-field - are there one within the qvd's it's different but even then you will need to separate them then their logical content will be different, too.
I hope this will be a good starting-point to go further: Get started with developing qlik datamodels.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Markus - but you just copied what I typed 
I already have a data load of the multiple dimension tables. Contatenating/merging them (as I mentioned) doesn't make a lot of sense because each table represents an entirely different entity which has its own attributes and one or more linking fields. It's a bit of a hierarchical model.
Regarding the timestamp - as I mentioned - this is an iterative load (incremental load) so a timestamp/last-reload-date is required. It is also required as I will be using it to map the change in dimensions over time (Slowly-Changing-Dimensions :: SCD Type 2)
Still looking for some advice on managing (or even if to manage) the synthetic key - potentially by creating a link table? As there are no Fact tables to concatenate, it would seem a link table would be the right way to go?
Thanks in advance.
Here is a snapshot of an initial view of the data model. Note only key fields are displayed for proprietary reasons.
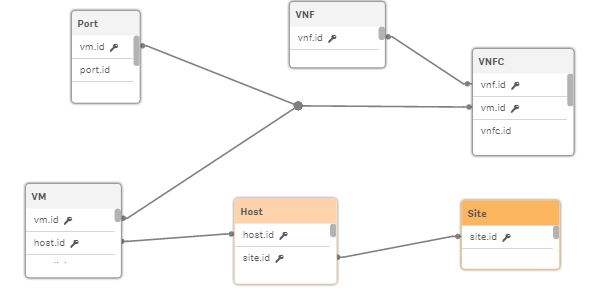
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here's a snapshot of a similar view with the timestamps added.
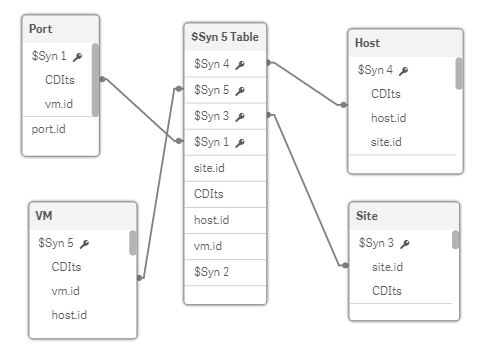
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It was not quite the same - I removed the ThirdID from the second load and all timestamps which aren't needed within the datamodel. You might need them of course for the qvd-creation but they are without any value as a single field within the datamodel rather the opposite - each one in a separate field is a different case but only useful if these fields will be used to search/select values or to calculate anything within the gui.
The model above could work well if the data in all tables are logical related and connected with the right keys. If not it will be necessary to change the datamodel by merging and/or splitting the tables/fields maybe with some additionally load-steps.
Are there data which aren't really related to eachother you shouldn't link them else keep them separate. For example I have a core data application with the core data from the articles, stores, staff and so on and all these data-areas are not connected - they don't belong together. This is like having multiple datamodels in one application.
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
See also: Create Timestamp for Incremental Load with no dates
- Marcus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Joey
I'll make some guesses as to your scenario
- The tables form a hierarchy
- Data is extracted daily
- Each day a date field is added to all the data
- The daily incremental load simply concatenates new data onto the existing tables
So maybe simply joining the table together could suffice.
Here are couple of simple Inline Load statements and a join
Data:
LOAD * INLINE [
Site, Date, Weather
SiteA, 01/01/2016, Sunny
SiteB, 01/01/2016, Cloudy
SiteA, 02/01/2016, Sunny
SiteB, 02/01/2016, Snow
];
Join (Data)
LOAD * INLINE [
Host, Site, Date, Temperature, HostID
HostA1, SiteA, 01/01/2016, Hot, 1
HostA2, SiteA, 01/01/2016, Hot, 2
HostB1, SiteB, 01/01/2016, Warm, 3
HostB2, SiteB, 01/01/2016, Warm, 4
HostA1, SiteA, 01/01/2016, Hot, 5
HostA2, SiteA, 01/01/2016, Hot, 6
HostB1, SiteB, 01/01/2016, Warm, 7
HostB2, SiteB, 01/01/2016, Warm, 8
HostA1, SiteA, 02/01/2016, Hot, 9
HostA2, SiteA, 02/01/2016, Hot, 10
HostB1, SiteB, 02/01/2016, Cold, 11
HostB2, SiteB, 02/01/2016, Cold, 12
HostA1, SiteA, 02/01/2016, Hot, 13
HostA2, SiteA, 02/01/2016, Hot, 14
HostB1, SiteB, 02/01/2016, Cold, 15
HostB2, SiteB, 02/01/2016, Cold, 16
];
Try this script in a sample qvf and see if it gives you the gist of what you after. You could maybe add some extra tables of sample data.
If it is adrift then maybe you could post the sample qvf to illustrate what is adrift.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Joey,
I will focus in your Port, VM and VNFC with a suggestion to get rid of the synthetic keys, as follow:
Port Table:
Would it be possible to alias its vm_id column as Port_vm_id (in the load script), by doing so, Port's vm_id will no longer become part of a synthetics key.
VNFC:
Its load statement will add a second vm_id column aliased to Port_vm_id, this will be the column to join with the port table and it will get rid of the synthetic key.
Your second diagram contains a column named CDIts, which you haven't defined in this thread, I assume it is the timestamp, if my assumption is correct, you should try to alias your stamp columns with non-conflicting names, so I will suggest names like Port_CDIts, Host_CDIts, the timestamp is a property unique to each table, therefore their names should be different.
Hope this helps.
A journey of a thousand miles begins with a single step.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
First of all - I appreciate all the responses. Sorry for the delayed reply, spent 3 days rebuilding my pc.
What I did that seems to work, though I would question its best-practice or potentially the future size - is this:
The load scripts for each table are 170+ lines of code where a hash is built and compared, changes are identified Active flags are set and qvds are built. So:
As I need each row to be timestamped according to it's incremental load and changes etc - and also, I need a common time dimension to be able to compare multiple dimensions, here's what I did:
CDIts is indeed the timestamp field (sorry for not clarifying)
For each table, I loaded a timestamp with a qualified name (ie port.CDIts)
I then created a master table at the end of all the table script loads that looks like this (below) joining all the tables.
It produces 1 master table with 39 fields (not too bad), then adds rows as data comes in and changes (I tested the incremental load part, and it works). Now I have a common timestamp field for all tables/rows where I can compare any dimension to another across a timeline. For if
Next step, build a master calendar (no problem).
Does anyone see any dilemmas in this model? Currently there are 6 'entity' loads which could double before this is done, so it's possible the column count potentially near 100.
Master:
LOAD *,
site.CDIts as CDIts
RESIDENT Site;
DROP Field site.CDIts;
Join (Master)
LOAD *,
host.CDIts as CDIts
RESIDENT Host;
DROP Field host.CDIts;
Join (Master)
LOAD *,
port.CDIts as CDIts
RESIDENT Port;
DROP Field port.CDIts;
Join (Master)
LOAD *,
vm.CDIts as CDIts
RESIDENT VM;
DROP Field vm.CDIts;
Join (Master)
LOAD *,
vnf.CDIts as CDIts
RESIDENT VNF;
DROP Field vnf.CDIts;
Join (Master)
LOAD *,
vnfc.CDIts as CDIts
RESIDENT VNFC;
DROP Field vnfc.CDIts;
DROP TABLES Site, Host, Port, VM, VNF, VNFC;
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello all,
I'm back at it. The resulting concatenated Master table was gargantuan (turned ~5k rows into 60M+) and the load time was unacceptable.
I have since created a link table that works - kind of. I'm looking for some specific advice on that please:
The Link table essentially looks like this (below):
Within each individual table, I have loaded the combination of fields represented in the Link table as %[Key field]
For example:
Host:
Load
*, host.id&'|'&site.id&'|'&CDIts as [%Key field]
From Host.csv;
Load
*, vm.id&'|'&host.id&'|'&CDIts as [%Key field]
From VM.csv;
I did this pursuant to: Concatenate vs Link Table
Now, this works much better (no synthetic keys and has a load time of under 3 seconds resulting in a table with ~10k rows), however you'll notice that [%Key field] is represented by different elements for each table (some have 2, some have 3, few are the same - ie, host has host/site/cdits, while vm has vm/host/cdits)
I'm finding that my data is askew a bit in the UI.
I've tried creating multiple composite keys, but it's resulting in even more synthetic keys and seems to be a catch22.
Any help would be outstanding.
Link:
Load distinct
[%Key field],
host.id,
site.id,
CDIts
Resident Host;
Drop fields site.id, host.id, CDIts from Host;
Concatenate (Link)
Load distinct
[%Key field],
site.id,
CDIts
Resident Site;
Drop fields site.id, CDIts from Site;
Concatenate (Link)
Load distinct
[%Key field],
vm.id,
host.id,
CDIts
Resident VM;
Drop fields vm.id, host.id, CDIts from VM;
Concatenate (Link)
Load distinct
[%Key field],
port.id,
vm.id,
CDIts
Resident Port;
Drop fields port.id, vm.id, CDIts from Port;
Concatenate (Link)
Load distinct
[%Key field],
vnf.id,
CDIts
Resident VNF;
Drop fields vnf.id, CDIts from VNF;
Concatenate (Link)
Load distinct
[%Key field],
vnfc.id,
vm.id,
vnf.id,
CDIts
Resident VNFC;
Drop fields vnfc.id, vm.id, vnf.id, CDIts from VNFC;