Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
Woohoo! Qlik Community has won “Best in Class Community” in the 2024
Khoros Kudos awards!
Announcements
Nov. 20th, Qlik Insider - Lakehouses: Driving the Future of Data & AI - PICK A SESSION
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Location and Language
- :
- Brasil
- :
- Re: Usar ou não o CONCATENATE???
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Creator
2015-07-10
10:27 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Usar ou não o CONCATENATE???
Ola a todos,
Estou com uma dúvida que muito venho trabalhando nela porem ainda não tenho total certeza de uma melhor pratica e acredito que muitos ja se deparou com esse problema.
Eu Tenho um DW que nele tenho diversas FATOS e DIMENSÕES, em uma mesma aplicação QLIK eu tenho que utilizar várias dessas FATOS e DIMENSÕES.
As Fatos e Dimensões são muito bem padronizadas, visto isso para customizar a carga de dados da aplicação e facilitar um suporte futuro no meu modelo de dados dentro da aplicação, eu optei por carregar todas as fatos que preciso e fazer um concatenate entre todas elas mantendo assim o meu modelo um starschema.
Mas como sabemos não é nada aconselhável relacionar FATO com FATO (que é que o CONCATENATE está fazendo), mesmo assim o fiz porque também a minha aplicação exige que que todas as minhas dimensões possa se relacionar com todas as FATOS.
Recentemente me deparei com um problema, precisei adicionar um novo campo em uma das FATOS mas somente em uma, e quando fiz isso muitas das informações que devo cruzar com essa estão apresentando algum problema, por exemplo, valor nulo.
Eu encontrei uma alternativa para resolver esse problema, mas em breve sei que terei outros problemas parecidos.
Eu estou planejando retirar o CONCATENATE das FATOS e dessa forma em fez de uma FATO serão várias dentro do meu modelo porem fazer com que todas as dimenssões se relacionem com todas as FATOS vai dar uma mão de obra muito grande.
O que vocês acham? devo prosseguir com essa ideia ou não?
vlw pessoal.
Att,
{kind=link}
2,348 Views
1 Solution
Accepted Solutions
Partner Ambassador/MVP
2015-07-10
10:25 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Vitor, boa noite.
Tem muita coisa no Qlik que a resposta é depende......
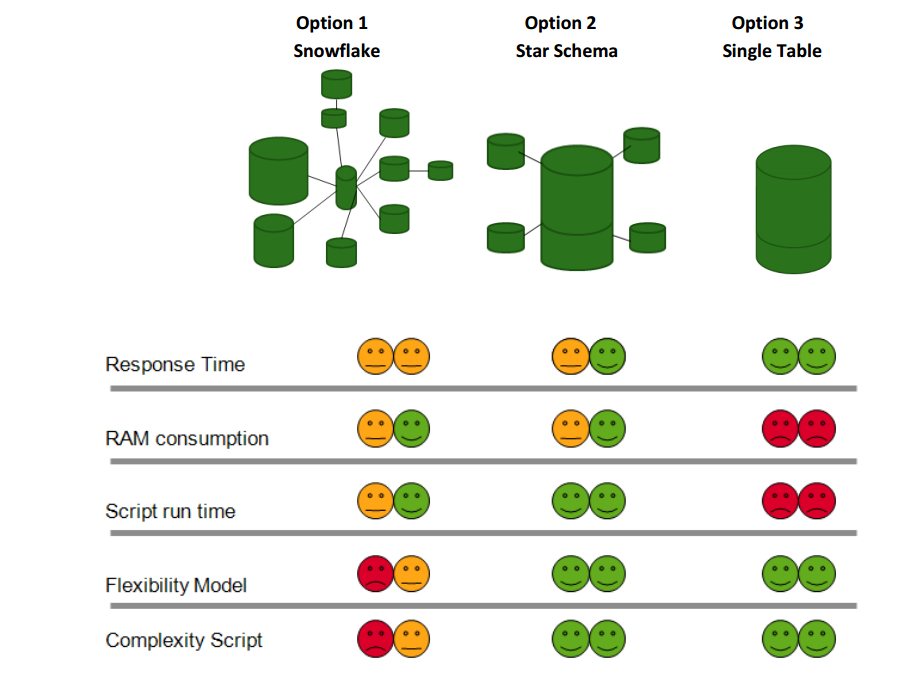
Dependendo da quantidade de registros, uma big fato vai consumir mais RAM mais sera mais rápida. Embora, em relação ao STAR não seja tao mais rápida assim. Então, não teremos uma forma que seja A CORRETA. Tudo depende.....Quantidade de registros,quantidade de campos, valores distintos, .....E se me permite falar, mesmo tendo um bom modelo, uma expressão mal feita poe tudo a perder.....
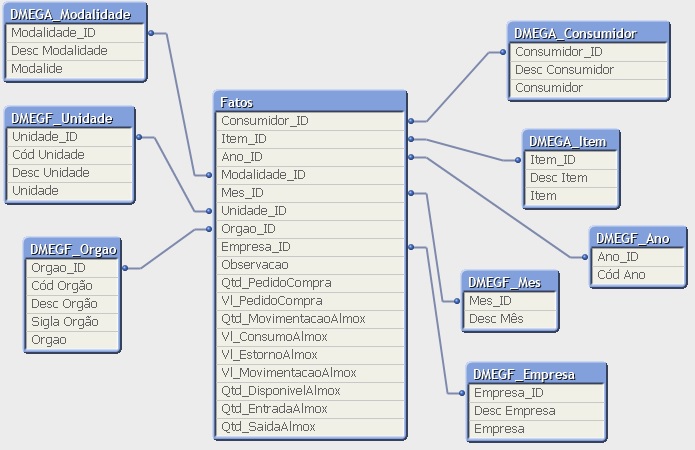
Segue uma imagem e um post do hic sobre esta questão de velocidade dependendo da quantidade de ligações.....
community.qlikview.com/blogs/qlikviewdesignblog/2015/01/19/number-of-hops?sr=stream&ru=4286
Particularmente, eu prefiro trabalhar com o modelo STAR (para mim, tanto a visualização das tabelas como o código fica mais fácil entender como dar manutenção).
Este outro blog tambem fala sobre modelagem....
qlikcentral.com/2014/08/19/the-optimal-qlikview-data-structure/
furtado@farolbi.com.br
7 Replies
MVP
2015-07-10
12:17 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Pode-se trabalhar com Concatenate ou LinkTable
Relate melhor o problema que esta tendo com o Concatenate
1,817 Views
Creator
2015-07-10
01:39 PM
Author
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Na verdade não problema com o concatenate e sim na técnica de modelar dentro do qlikview, com o concatenate eu acabo fazendo todas as fatos em uma só e isso está causando problema todas vez que é necessário adicionar um novo campo em alguma das fatos, queria saber se vale a pena deixar de utilizar o concatenate e em fez de uma fato utilizar varias dentro do meu diagrama
1,817 Views
Partner Ambassador/MVP
2015-07-10
10:25 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Vitor, boa noite.
Tem muita coisa no Qlik que a resposta é depende......
Dependendo da quantidade de registros, uma big fato vai consumir mais RAM mais sera mais rápida. Embora, em relação ao STAR não seja tao mais rápida assim. Então, não teremos uma forma que seja A CORRETA. Tudo depende.....Quantidade de registros,quantidade de campos, valores distintos, .....E se me permite falar, mesmo tendo um bom modelo, uma expressão mal feita poe tudo a perder.....
Segue uma imagem e um post do hic sobre esta questão de velocidade dependendo da quantidade de ligações.....
community.qlikview.com/blogs/qlikviewdesignblog/2015/01/19/number-of-hops?sr=stream&ru=4286
Particularmente, eu prefiro trabalhar com o modelo STAR (para mim, tanto a visualização das tabelas como o código fica mais fácil entender como dar manutenção).
Este outro blog tambem fala sobre modelagem....
qlikcentral.com/2014/08/19/the-optimal-qlikview-data-structure/
furtado@farolbi.com.br
Former Employee
2015-07-11
06:02 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I strongly disagree with the summary in the picture. A snowflake is much better than what the table indicates. And the single table is worse. My take on it would be the following picture:
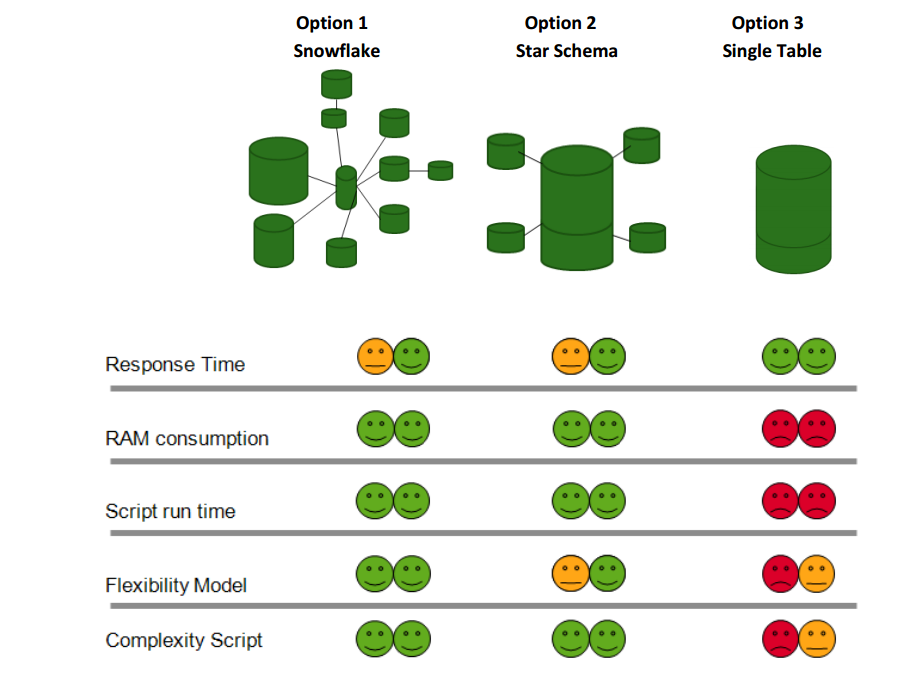
HIC
Partner Ambassador/MVP
2015-07-11
10:11 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Henric. Whom will disagree about it? If you say, must be truth.....You are my guru.
Thanks for share this picture.
I have many documents from Qconnections (since 2011) ,books and also I read a lot of blogs (special your blog..) but never seen different from my picture. Is this like count(distinct ) myth? ( A Myth About Count(distinct …)
Was true in earlier versions?
And about QIX engine ? This is true too?
Sorry about this questions, but I know (until now...) that if I use fields from different tables in an expression, Qlik will "on fly" join this fields from differents table to calculate. This consume RAM and CPU. With many hops and millions of records, still the performance the same? If I use aggr() I know that will create a virtual table to evaluate it and in this case, with many hops will be the same (performance)?
PS - If you prefer, I can open a new post with these questions...
AMF
furtado@farolbi.com.br
Former Employee
2015-07-13
07:37 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It's partly a myth, partly true...
It is a myth because a well designed snowflake is just as efficient as a star. There is no reason to avoid it.
But it's partly true, because it is easy to make mistakes:
- If the data model contains two or more very large tables, it will be slow. So, imagine a snowflake where you have both an Orders table, and an OrderLines table. Both are potentially large, so the application can be slow. Solution: Join these two tables - but keep the other branches in the snowflake. You will now have an efficient snowflake.
- If you have an aggregation with fields from different tables, e.g. Sum( OrderLines.Quantity * Products.ListPrice ), you will also have a slow application. Solution: Move the ListPrice to the Fact table. You will now have an efficient snowflake.
HIC
Creator
2015-07-13
09:09 AM
Author
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Muito obrigado a todos.
Me ajudou muito, estou revendo o meu modelo no DW para ver o que posso melhorar para que no QLIK eu consiga otimizar o meu modelo
1,817 Views